两小时激辩:黄仁勋为什么不怕 TPU、不怕华为、不怕出口管制?
宝玉

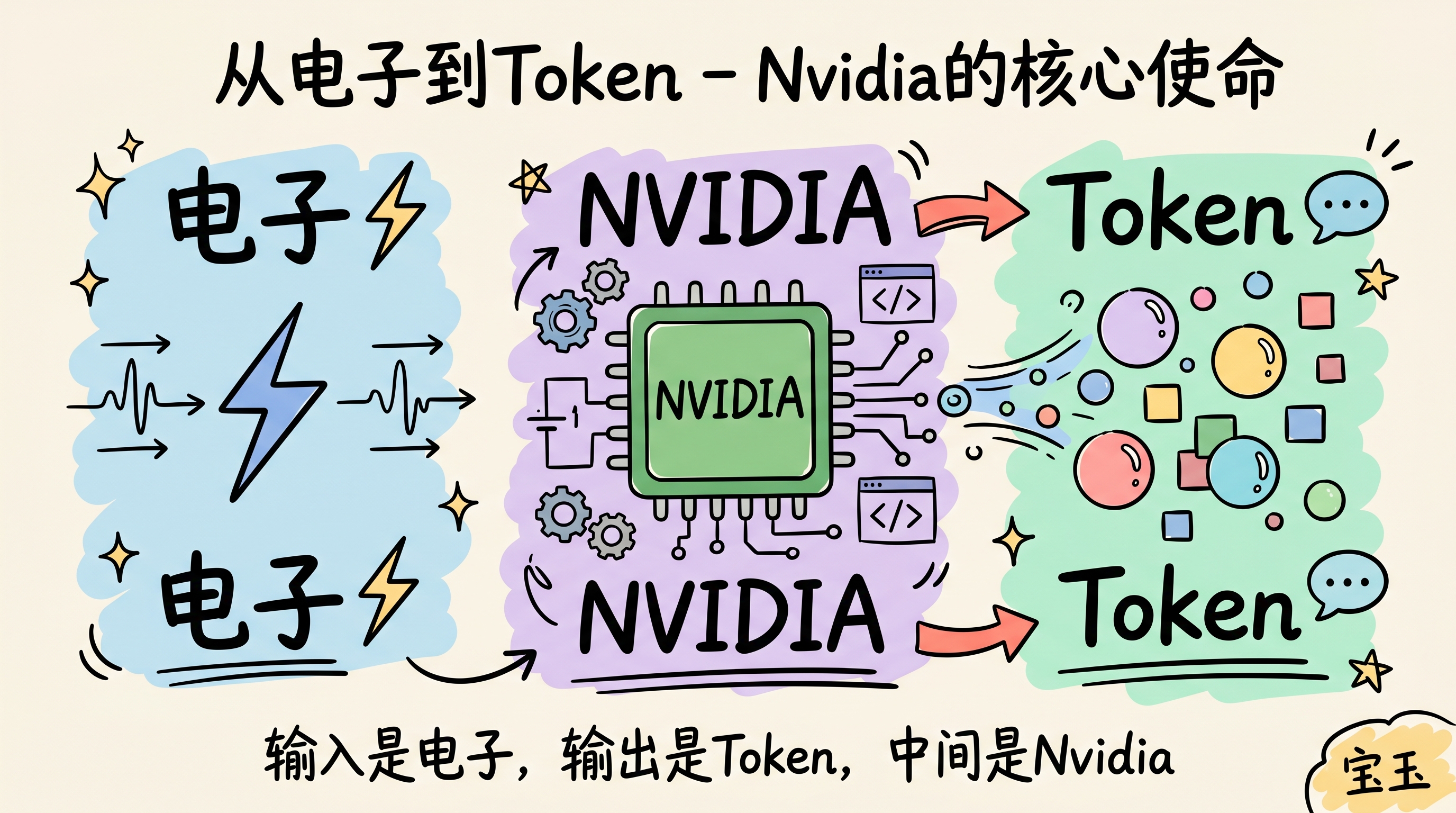
黄仁勋最近接受了 Dwarkesh Patel 长达两个小时的高密度专访。这场访谈没有客套寒暄,只有密集的观点碰撞。如果你没时间看完,那就记住这一句话——掌控全球 AI 基础设施命脉的老黄,用这样一句话定义了 Nvidia 的使命:
“输入是电子,输出是 Token,中间是 Nvidia。” (“The input is electron, the output is tokens. That is in the middle, Nvidia.”)
整场对话的气氛激烈又直白。主持人 Dwarkesh 在每个话题都紧追不放,尤其涉及中国芯片出口时,两人更是直接“杠”了整整二十分钟。老黄强烈反对把 AI 芯片当作武器的类比,而 Dwarkesh 则紧盯着刚发布不久、网络攻击能力惊人的 Anthropic Claude Mythos 模型,穷追猛打。

访谈来源:Dwarkesh Patel Podcast(2026 年 4 月初) 原始视频:YouTube 链接
要点速览
- Nvidia 的经营哲学是“少做,但每件事都是独一无二”。这也是为什么 Nvidia 不做云、不押注赢家、不竞价分配 GPU。
- 供应链的瓶颈最多两三年就能解决,真正制约未来的是能源政策,而非芯片产能。
- CUDA 的壁垒不是技术锁定,而是庞大的 GPU 装机量、丰富的生态系统,以及在不同云平台之间的可移植性。Nvidia 还直接派驻工程师帮 AI 公司优化模型,通常能轻松提升模型速度 2-3 倍。
- Anthropic 使用 TPU 和 Trainium 是特殊个案而非趋势,原因在于早年 Nvidia 没及时投资 Anthropic,逼得后者只能依靠 Google 和 Amazon 的芯片生态。
- 中国早已拥有足够的 7nm 芯片产能和大量能源,限制出口根本挡不住 AI 发展,反而会推动中国芯片的完全自主化,让美国白白丢掉全球第二大科技市场。
- Nvidia 收购 Groq 不是因为自家 GPU 架构不行,而是因为推理市场的 Token 已经贵到可以分档收费了。
【1】从电子到 Token:Nvidia 如何定义自己?
一开场,Dwarkesh 就抛出一个尖锐的问题:如果 Nvidia 的工作本质是写软件,而 AI 又正在把软件逐渐商品化,那 Nvidia 自己会不会也被商品化?
老黄干脆直接把问题推翻重来:“把电子转化成 Token,这事儿本身几乎没法被商品化。”因为这个转化过程不仅复杂,而且远未被充分理解。他强调 Nvidia 的哲学是:
“做必要的事情,越少越好。” (“We should do as much as needed, as little as possible.”)
这句话贯穿了整个访谈,解释了 Nvidia 为什么不自己做云,不偏向某个赢家,也不搞竞价分配 GPU。
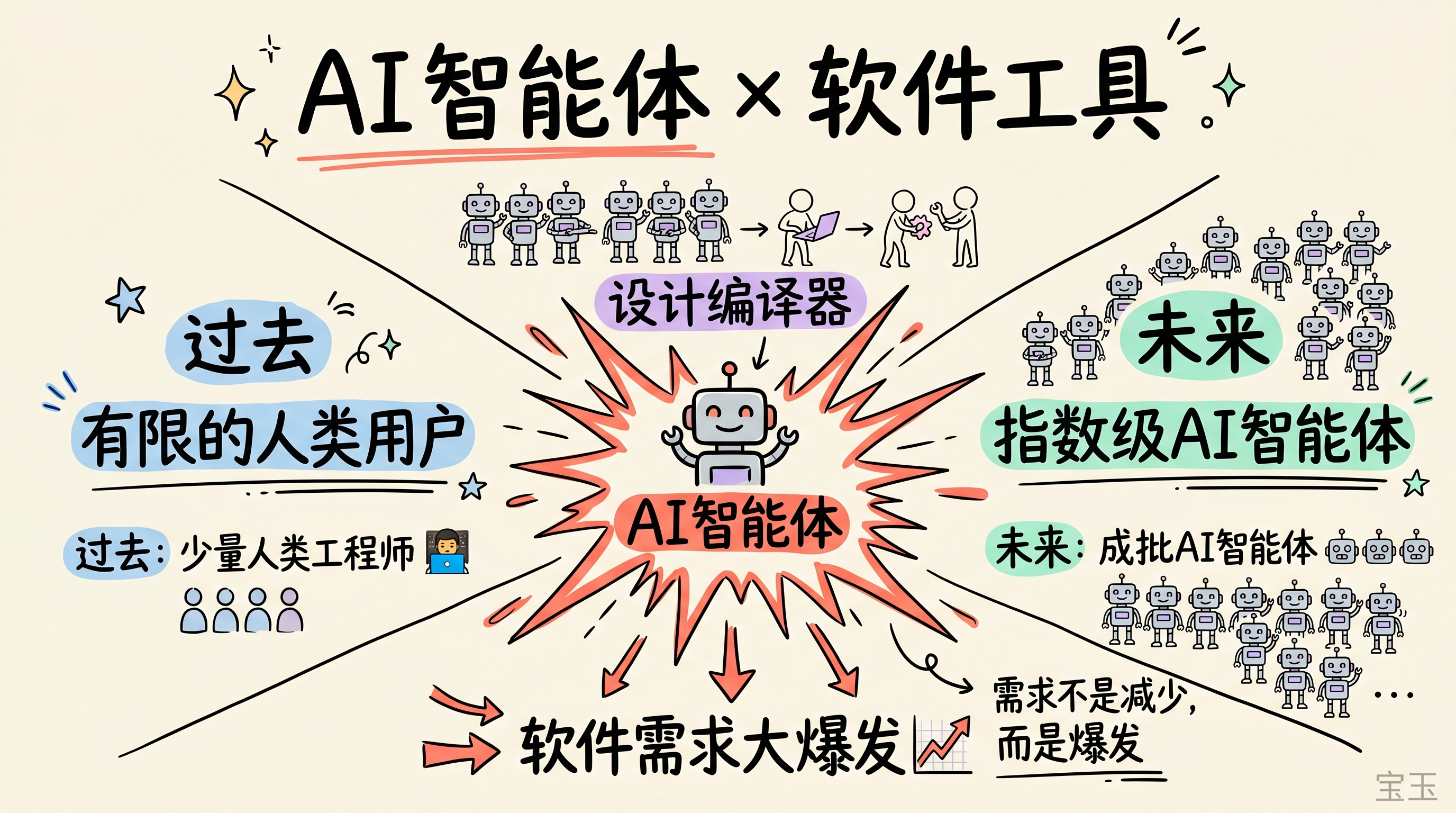
而针对“AI 会不会让软件公司贬值”这个反直觉问题,老黄的观点恰好相反。他认为未来 AI 智能体的数量将指数级增长,这些智能体需要大量使用现有的软件工具,而过去这些工具只能由有限数量的人类工程师操作。
他举了个生动的例子:芯片设计公司 Synopsys 的设计编译器(Design Compiler),未来的使用实例可能会爆炸式增长——因为 AI 智能体将成批地使用这些工具进行设计探索。这不仅不会淘汰软件公司,反而会带来史无前例的需求大爆发。
老黄总结道:“今天智能体还不擅长使用这些工具,未来要么工具公司自己开发智能体,要么智能体自动变聪明,学会高效使用工具。这两个过程会同时发生。”
【2】当供应链“布道者”:老黄如何推动整个产业链?
访谈中,Dwarkesh 直接戳中了 Nvidia 看似牢不可破的护城河——他援引了最新财报里的千亿美元采购承诺,以及 SemiAnalysis 更高的 2500 亿美元估值,质疑 Nvidia 是不是靠“买空市场”卡住了竞争对手。
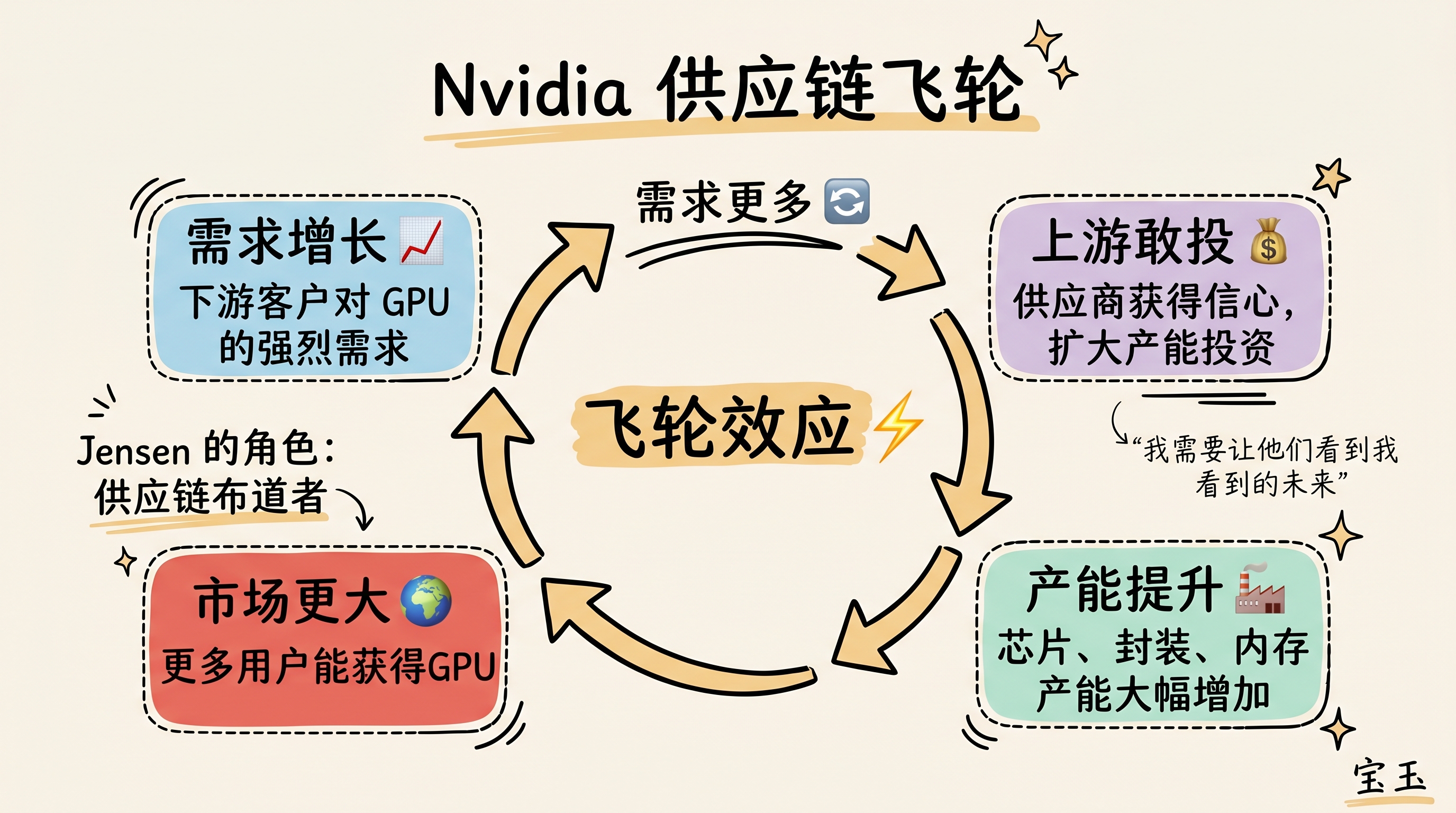
老黄没否认这点,但强调事情没这么简单。Nvidia 敢砸出这么多钱的根本原因,是下游需求足够大,给了供应商十足信心去扩产:
“需求多 → 上游敢投 → 产能增 → 市场更大 → 需求更多”, 这是 Nvidia 背后真实运转的飞轮。
但这飞轮并不是自动转起来的。老黄形容自己花了大量精力做供应链“布道者”,挨个儿向上下游 CEO 讲清楚 AI 大潮为什么会来、什么时候来、以及将有多大:
“我需要让他们看到我看到的未来。”
他特意讲了与美光(Micron)CEO Sanjay Mehrotra 的关键对话,详细告诉对方为何 HBM(高带宽内存)市场马上会爆炸式增长。后来事实证明,美光押注 HBM 和 LPDDR 是个极为成功的决策。
在更上游的光通信领域,Nvidia 直接牵头重塑了供应链:和台积电一起开发封装技术,创造新工艺,还主动把专利分享给合作伙伴,并直接投资帮他们扩大产能——最近对 Lumentum 的 20 亿美元投资,就是典型案例。
老黄把 Nvidia 每年举办的 GTC 大会,定义为产业链上下游的集体“思想升级”:
“有人总跟我说『Jensen,你演讲有时像在上课』,但这正是我要做的事。我希望产业链上的所有人,都能像我一样清晰地看到 AI 即将到来的巨大机会。”
【3】产能瓶颈?不存在的
访谈到这里,Dwarkesh 再次追问了一个尖锐问题:Nvidia 已经占据了台积电 3nm 产能的绝大部分,2026 年甚至达到 60%,2027 年更要占到 86%。在如此巨大的基数下,Nvidia 怎么可能再翻倍增长?
老黄的回答异常乐观,他直截了当地表示:
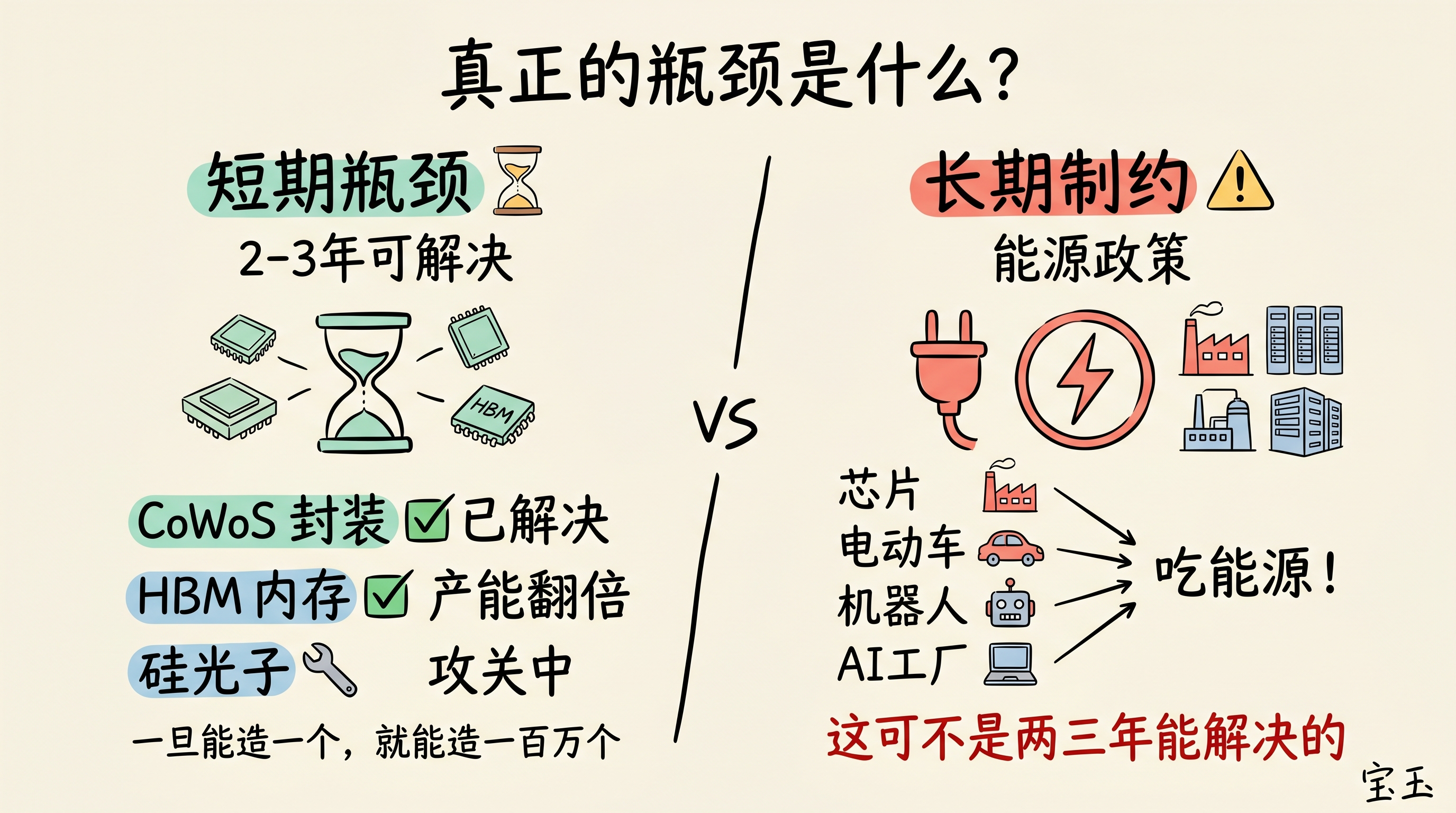
“所有产能瓶颈最多持续两三年。一旦你能造一个,就能造一百万个。”
任何时候,瞬时需求都会超越供应能力,瓶颈可能出在你完全想不到的环节,甚至可能是水管工人——“明年 GTC 我们还真邀请了水管工参加。”
他以 CoWoS(台积电用来集成芯片和高带宽内存的先进封装技术)为例,两年前它还是 AI 芯片的最大瓶颈,Nvidia 花了大力气解决,现在产能已经翻了数倍。
更重要的是,Nvidia 提前数年就开始主动预判瓶颈。比如硅光子(用光传输数据)领域,Nvidia 不仅亲自开发关键技术,还投资并与台积电及合作伙伴联手扩产,完全掌握供应链的主动权。
但老黄强调,真正让他担忧的并非这些硬件瓶颈,而是下游能源政策:
“没能源,你什么产业都建不了,更别提再工业化美国了。芯片、电动车、机器人、AI 工厂,这些都吃能源,而能源问题可不是两三年就能解决的。”
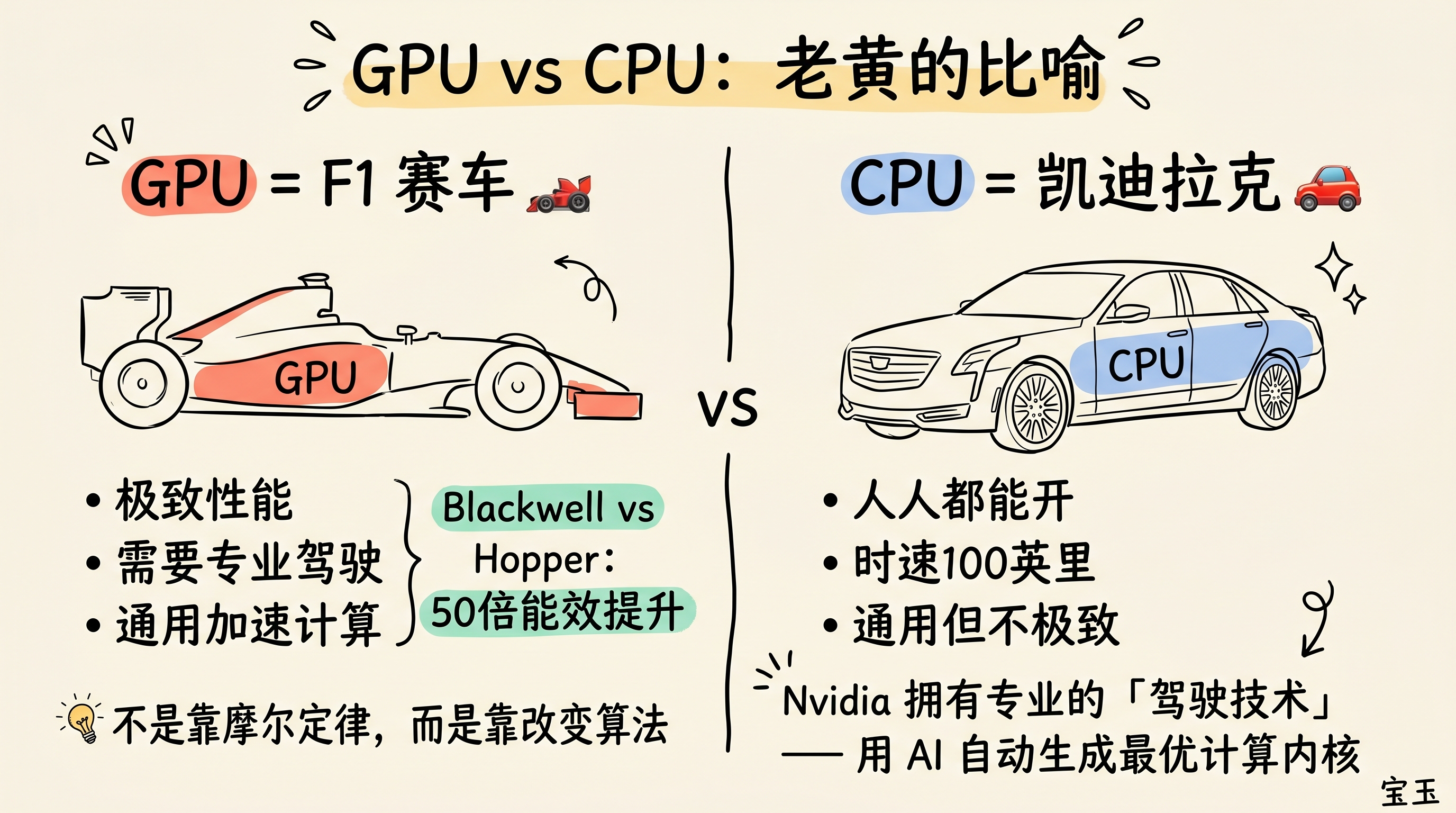
【4】GPU vs TPU:F1 赛车还是凯迪拉克?
访谈到这里,Dwarkesh 又抛出了一个犀利的观点:世界上最强的两个 AI 模型——Claude 和 Gemini,都是用 Google 的 TPU 训练出来的。这是不是意味着 Nvidia 已经落后了?
面对这个挑战,老黄迅速把讨论格局拉大:“Nvidia 做的不是『张量处理单元』,而是更广泛的『加速计算』。”除了 AI,Nvidia 的 GPU 还能覆盖分子动力学、流体力学、量子计算、数据处理等数十个领域。这种广泛的适用性,是专用芯片(ASIC)无论如何也追不上的。
而且更关键的是,Nvidia 是云计算领域的通用基础设施,任何人都能操作,能跑在 Google、Amazon、Azure、OCI 等所有主流云平台上。但 TPU 和 Trainium 这些芯片就不同,只能被特定的云服务商使用。
Dwarkesh 显然对这个解释不买账。他代表一些 AI 研究者指出,TPU 本质上就是专门优化矩阵乘法的脉动阵列(systolic array),简单、高效,而 GPU 的通用性反而成了浪费:“做 AI 就是反复的矩阵计算,你非得弄个能做其他事情的 GPU,晶体管面积不是白瞎了吗?”
对此,老黄坚决反驳:“矩阵乘法当然重要,但不是 AI 的全部。如果你想试试新的注意力机制、融合不同的模型架构,你就需要 GPU 这种通用计算平台。”
然后他直接给出了数据——新一代的 Blackwell 架构相比 Hopper 架构能效提高了整整 50 倍:
“靠摩尔定律,每年最多提升 25%。但你要实现 10 倍甚至 100 倍的飞跃,唯一的方法就是不断改变算法和计算方式。”
老黄特意提到,最初宣布 Blackwell 比 Hopper 能效高 35 倍时,没人相信。直到 SemiAnalysis 独立分析后,才发现实际提升居然达到 50 倍!而这一突破的背后,靠的不是制程升级,而是处理器架构、算法、分布式计算策略,以及 NVLink、Spectrum-X 等网络技术的全面创新。
最后,老黄以一个生动的比喻结束:
“GPU 就像 F1 赛车,CPU 更像凯迪拉克。凯迪拉克人人都能开到时速 100 英里,但想把 F1 赛车推到极限,你必须拥有专业的驾驶技术。”
而 Nvidia 自己就拥有这种专业的“驾驶技术”——用 AI 自动生成最优计算内核,帮客户轻松将性能提升 2 倍甚至更多。“考虑到现在 Hopper 和 Blackwell 在全球的装机量,这 2 倍的性能提升,直接等于客户收入翻倍。”
【5】CUDA:生态便利还是技术锁定?
访谈中 Dwarkesh 再次犀利提问:如果 Nvidia 60% 的收入都来自少数几个巨头客户,而这些客户完全有资源自己写内核,那 CUDA 到底还有多大优势?Anthropic 和 Google 已经开始主推自己的芯片,连依赖 Nvidia GPU 的 OpenAI 都开发了 Triton 框架,让内核编程不再依赖 CUDA。
面对这个问题,老黄一口气给出了三个层面的答案:
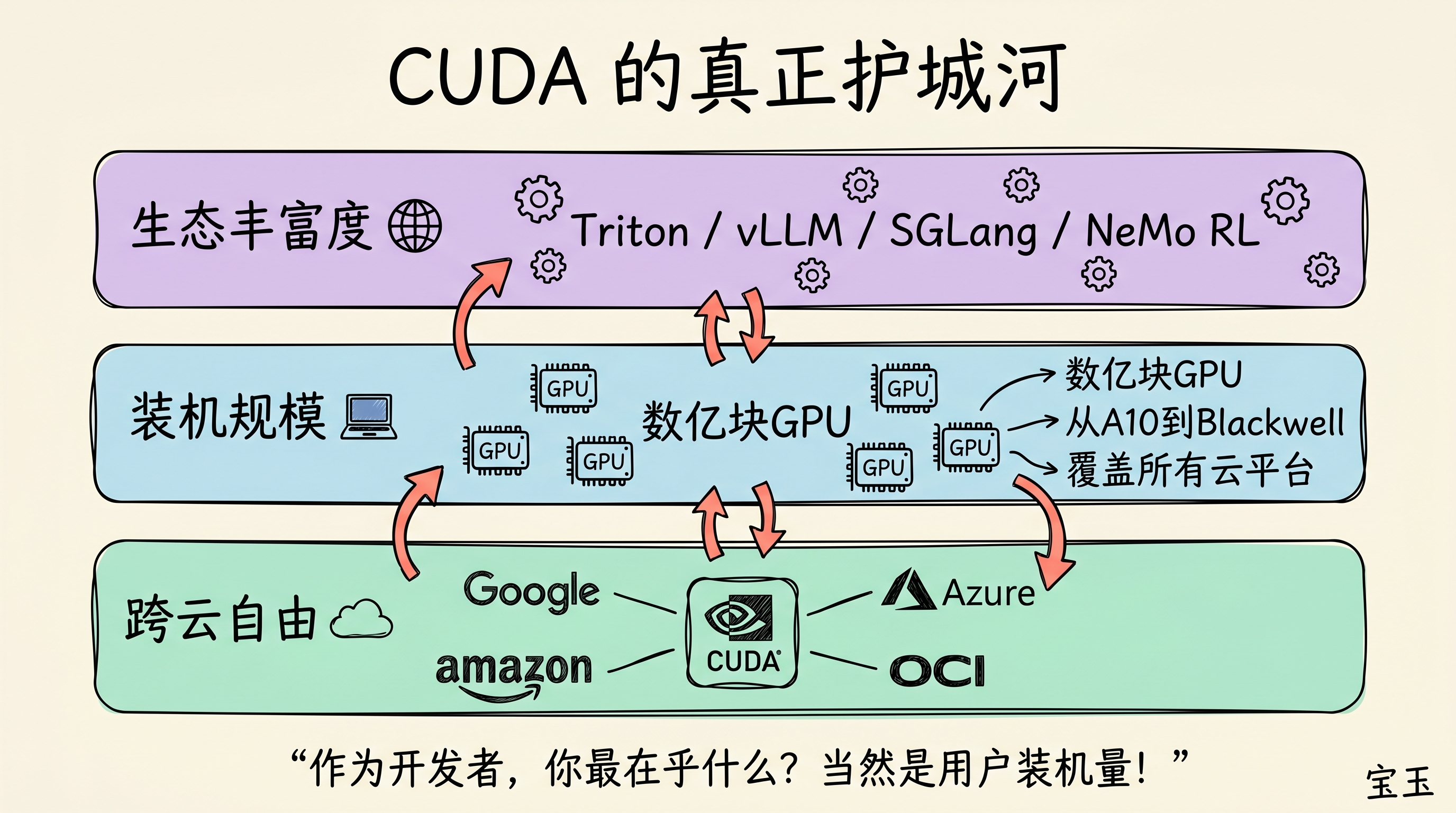
第一,是生态的丰富程度。 CUDA 已经支持了几乎所有主流框架,从 OpenAI 的 Triton,到 vLLM、SGLang,再到最新的强化学习框架 Verl 和 NeMo RL。Nvidia 自己也积极参与 Triton 的底层开发,这意味着如果出了问题,你至少明确知道问题出在自己代码上,而不是无底洞般的底层实现。
第二,是庞大的装机规模。 “作为开发者,你最在乎什么?当然是用户装机量!” Nvidia 在全球拥有数亿块 GPU,从老旧的 A10 到最新的 Blackwell,横跨各个云平台、每个垂直领域。无论你是做云服务还是机器人,你都希望自己的代码随时随地能跑起来,而 CUDA 就能保证这一点。
第三,是跨云平台的自由。 Nvidia 是唯一一个能同时存在于 Google、Amazon、Azure 和 OCI 等所有主流云服务上的芯片公司。AI 公司无法确定自己未来会选哪家云服务,因此 Nvidia 能提供最大的灵活性和安全感。
但 Dwarkesh 还是不依不饶:这些优势对那些顶级客户真的有那么重要吗?当 AI 越来越擅长自己写高效内核时,Nvidia 会不会变成单纯拼性能和价格的芯片商?到那个时候,Nvidia 还能维持超过 70% 的高毛利率吗?
对此老黄非常自信地回应:“Nvidia 工程师优化的不只是内核,而是客户整个技术栈。”
他说,没有人比 Nvidia 自己更懂 Nvidia 的架构,“我们的每瓦性能和总拥有成本(TCO)都是全球最好的,没有例外。”
他甚至公开喊话 TPU 和 Trainium 等竞争对手:“我鼓励他们站出来,用 Inference Max 这种公认的基准测试证明自己的推理性能。但现实是,他们根本不敢来。”
最后,老黄指出了一个容易被忽视的重要细节: 虽然 Nvidia 60% 的收入确实来自几家超大型云厂商,但这些 GPU 大部分最终服务于外部客户。云厂商愿意大规模采购 Nvidia,是因为 Nvidia 本身带来了最多的客户。这才是 Nvidia 真正的生态护城河。
【6】Anthropic 的芯片选择:老黄承认了一个错误
访谈最有意思的地方,莫过于老黄公开解释 Anthropic 为什么大量使用 Google 的 TPU 和 Amazon 的 Trainium。
Dwarkesh 提到了 Anthropic 刚宣布的与 Google 和 Broadcom 总计 3.5GW 算力规模的 TPU 交易,尖锐地问道:“如果 Nvidia 性价比真的全球第一,Anthropic 为什么还要选别家的?”
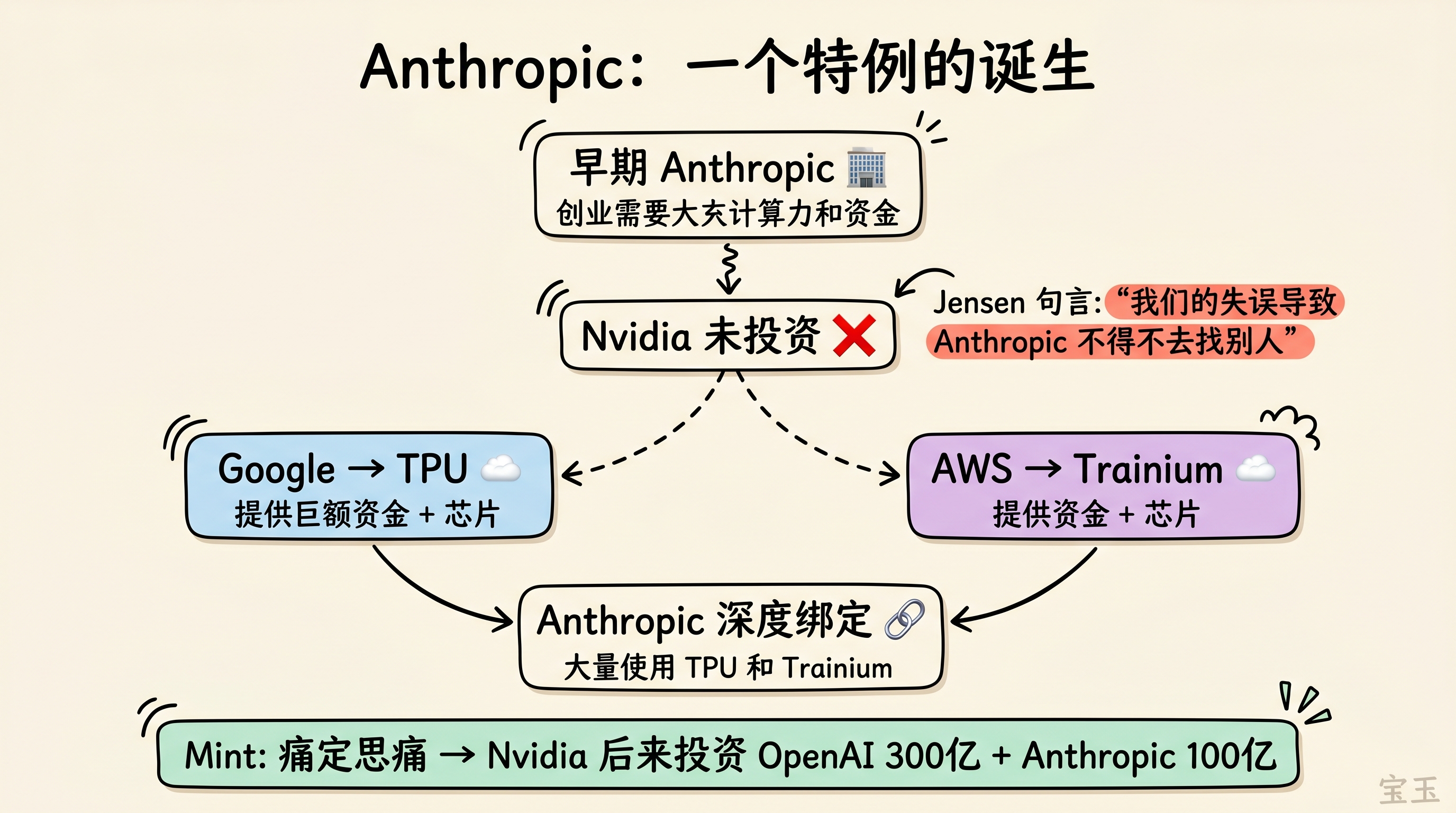
对此,老黄的回应非常直接:“Anthropic 是一个特例,不是趋势。”
他甚至夸张地表示:
“没有 Anthropic,TPU 哪来的增长?100% 是靠 Anthropic。没有 Anthropic,Trainium 的增长从哪来?还是 Anthropic。”
虽然现实情况并没有老黄说得这么绝对,但他的核心意思其实很明确——在 Nvidia 所有的重要客户中,只有 Anthropic 明显地偏向了其他芯片生态。
更有意思的是,接下来老黄主动承认了自己过去的一个重大失误:
“很久以前,我们确实没能力这么做。我低估了建立一家像 OpenAI 或 Anthropic 这样的大模型实验室有多难,也低估了它们对供应商巨额资金支持的需求。当时 Nvidia 根本拿不出 50 亿、100 亿美元给 Anthropic,但 Google 和 AWS 能做到。”
他直言不讳地说:
“我们的失误导致 Anthropic 不得不去找别人。但即使这样,我仍然为 Anthropic 的存在感到高兴——Anthropic 对世界是有益的。”
后来老黄痛定思痛,决心不再犯同样的错误,因此 Nvidia 后续大手笔投资了 OpenAI(300 亿美元)和 Anthropic(100 亿美元)。
关于 Nvidia 为什么不自己做云服务,老黄再次强调了他核心的经营哲学:
“如果我们不冒险打造计算平台,真的就没人做了。如果没有 NVLink、CUDA 和整个生态的搭建与投入,AI 产业根本不会有今天的繁荣。但云服务不同,世界上有很多人能做。我们不做,自然会有人去做。”
他强调 Nvidia 不会亲自做融资业务,因为“融资业务市场上已经有很多人在做了,我们宁愿跟所有做融资的人合作。”
至于为什么 Nvidia 从来不去押注某个赢家,老黄回忆起创业时的教训:“我们刚起步的时候,全行业有 60 家 3D 图形公司。要是那时候投票选谁最可能失败,我们绝对排第一,因为我们的架构方向根本就是错的。”
最后老黄总结道:
“我足够谦逊地知道,不要去挑选赢家。要么大家自己想办法活下去,要么我们干脆照顾好所有人。”
【7】GPU 定价哲学:不涨价、不竞标的理由
访谈中,Dwarkesh 又抛出了一个让人直觉上觉得“这才合理”的问题:“GPU 紧缺时,为什么不直接卖给出价最高的人?”
对此老黄给出了一个出人意料但底气十足的回答:
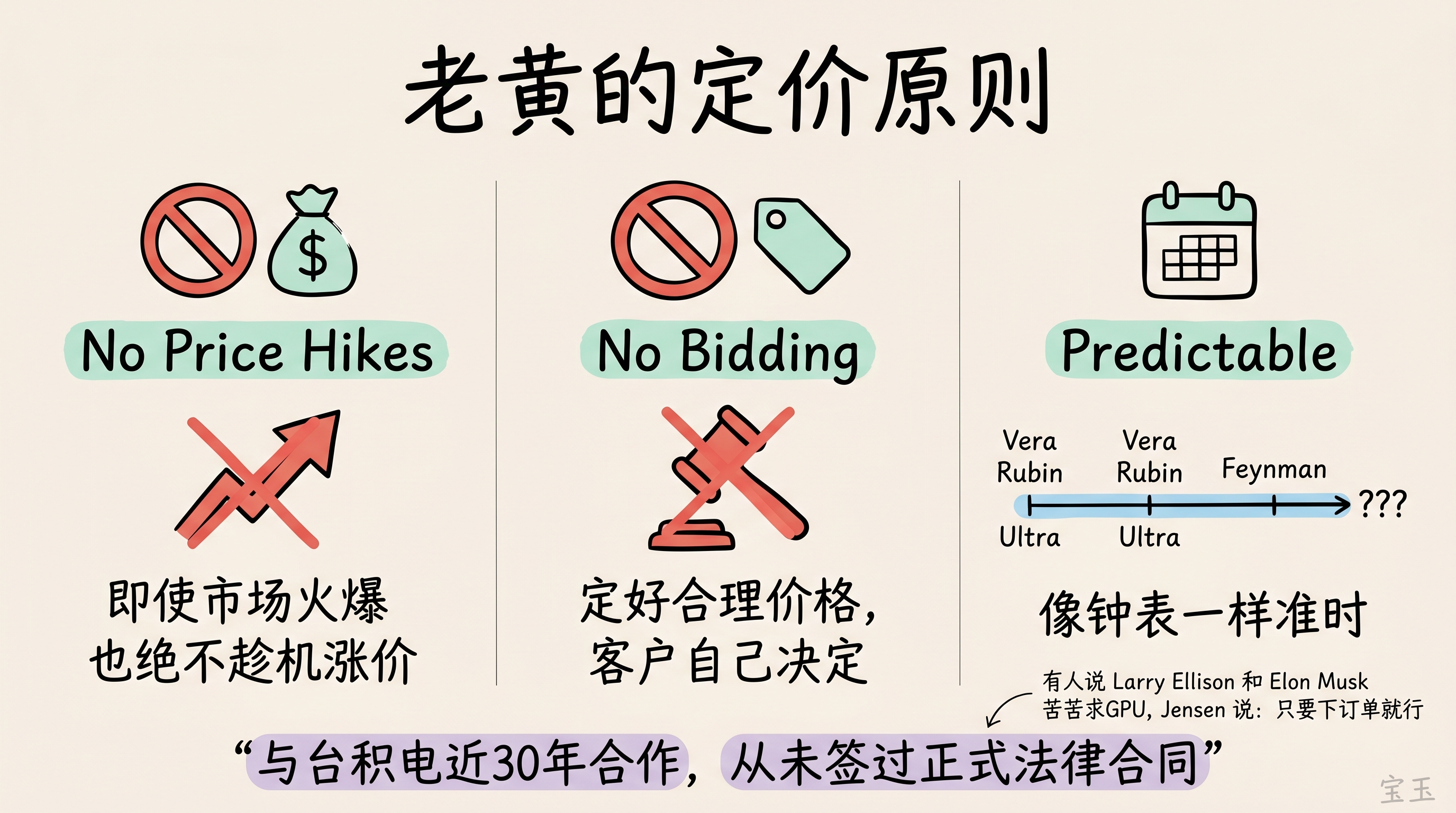
“我们从来不做竞价分配 GPU 的事。这不是 Nvidia 的风格,我们只负责定好一个合理的价格,客户自己决定买不买。”
老黄强调,即使市场火爆到爆炸,他们也绝不会趁机涨价:“其他芯片公司可能会,但我们绝不。我们想做整个行业可信赖的基石,让客户永远不需要猜测或担心我们会不会趁机割韭菜。”
他甚至顺带辟了个谣:“坊间传闻 Larry Ellison 和 Elon Musk 曾经在一次晚餐上苦苦求我分 GPU 给他们,这事确实有,但他们根本不用求,只要下订单就可以了。”
更让人吃惊的是,老黄透露 Nvidia 与台积电近 30 年的合作,从来没签过正式法律合同:
“我们之间一直存在一种默契,有时候我占点便宜,有时候吃点亏,但总体上公平。我可以完全信任他们、依赖他们。”
最后,他点出了 Nvidia 的另一个优势——超强的可预测性:
“今年我们交付 Vera Rubin 架构,明年是 Vera Rubin Ultra,后年是 Feynman,再下一年还有未公布的新架构。”
他带着骄傲地总结道:
“你放眼全球,有哪家 ASIC 团队敢拍胸脯承诺:每年稳定推出新架构、每年 Token 成本持续下降一个数量级?只有 Nvidia 能做到,我们像钟表一样准时可靠。”
【8】对华出口管制:老黄全场最激烈的交锋
访谈进行到中段时,Dwarkesh 开启了本场最激烈的 20 分钟辩论。他直言,自己习惯当“魔鬼代言人”——此前他曾挑战过支持出口管制的 Dario Amodei,现在面对反对管制的老黄,他反过来问了同样尖锐的问题:
“如果中国企业和政府拥有了训练出类似 Anthropic Claude Mythos 这种顶级模型的 AI 芯片,会不会威胁美国国家安全?”
Claude Mythos 近期刚发布,就已发现了数千个零日漏洞,甚至能在主流操作系统和浏览器中自主发掘高危漏洞。正因如此,Anthropic 不敢公开发布,只限量提供给 Google、微软等机构修补漏洞。
对此老黄迅速而坚定地反驳:“Mythos 训练所需的算力其实并不特殊,在中国早已普遍存在。他们有世界 60% 以上的芯片产能,拥有最顶尖的计算机科学家,全球 50% 的 AI 研究者也都来自中国。”
他更犀利地提出:“如果你真担心中国,用最糟糕的方式——把他们变成受害者、敌人,肯定不是好主意。”
老黄指出,现在美中最大的缺失,是 AI 研究者之间的真正对话。他认为双方应该公开、直接地讨论,明确 AI 哪些领域不能涉及。
Dwarkesh 不认同老黄的观点。他强调,中国虽然芯片多,但先进算力只有美国的十分之一,因为中国的制程还卡在 7nm,没有 EUV 设备。这意味着美国有一个宝贵的窗口期,可以比中国更快达到 Mythos 的级别,并提前堵上漏洞。
老黄却一针见血地指出了被忽略的现实:
“中国拥有的免费能源实在太惊人了。AI 就是一个巨大的并行计算问题,如果中国芯片算力不够先进,他们完全可以用大量便宜芯片和几乎免费的电力拼成超算。他们甚至有空置的鬼城、鬼数据中心,可以迅速规模化部署。”
他进一步补充道:“7nm 芯片其实就是我们过去的 Hopper 芯片,而全球绝大部分先进 AI 模型,就是用 Hopper 训练出来的。华为去年更是创下了史上最大规模的单年芯片出货量。”
在老黄看来,出口管制只会促使中国更快走向芯片自主,而美国则将因此白白放弃全球第二大的科技市场。
Dwarkesh 试图用“内存带宽”问题继续施压,但老黄干脆回应:“华为本质上是一家网络公司,他们完全有能力通过先进的互联技术,把大量普通芯片串联成超级计算机。他们甚至已经展示过用硅光子技术把低端芯片变成巨型超算的能力。”
随后,老黄抛出了访谈中最具争议的一句话:
“如果未来 DeepSeek 这样的顶尖模型,首发选在华为芯片上,那对美国来说将是灾难。”
他的逻辑非常清晰:如果开源 AI 模型被优化到非美国的技术栈上,当这些模型传播到全球南方、中东和东南亚地区时,美国的技术标准和硬件生态将不再有竞争力,美国将丢掉全球 AI 技术主导权。
Dwarkesh 随即反驳道:“Anthropic 的模型同时能跑在 GPU、TPU 和 Trainium 上,这种跨平台兼容性不会轻易消失。”
老黄不以为然:“你试试看,把一个为 Nvidia 优化的模型搬到其他平台上去,性能会怎么样?Nvidia 的成功就是最佳证明。AI 模型在我们的技术栈上被创造,也在我们的技术栈上达到最好效果,这点毫无疑问。”
接下来,Dwarkesh 引用了 Dario Amodei 曾在达沃斯论坛上的尖锐比喻:“Nvidia 卖芯片给中国,就像波音自豪地说,朝鲜的核武器导弹外壳是波音造的,所以这是支持美国技术生态。”
这句话立刻激怒了老黄,他强烈回击:
“你把 AI 和你刚刚提到的任何东西比较,简直是荒谬透顶。”
Dwarkesh 仍不罢休:“但如果他们的芯片可以跑出攻击所有美国软件的 AI 模型,这难道不算武器?”
老黄冷静地指出:“真正解决之道,是美中通过沟通达成明确共识,确保所有国家都不滥用 AI 技术。更何况,中国是全球最大开源贡献者,AI 安全依赖于全球开源生态。我们不能掐死它。”
Dwarkesh 抓住老黄逻辑上的微妙矛盾追问:“你一边说 Nvidia 芯片最强,在中国市场一定能赢;一边又说,就算不卖芯片,中国照样可以做到一样的事。”
老黄强调,这两点并不矛盾:“如果市场上有更好的芯片,自然选更好的。如果没有,也能用已有的方案,这完全合乎逻辑。”
辩论到最后,双方立场都非常鲜明:
老黄坚持,AI 技术像一块“五层蛋糕”,每一层都必须竞争并取胜。牺牲芯片层(也就是不卖芯片给中国)来防止他们训练出高端模型,是一种极端且短视的做法。他举了美国电信行业的例子:过去严格的出口管制曾让美国公司彻底丢掉全球电信市场,最终让美国“不再控制自己的电信产业”。
Dwarkesh 激烈地质问老黄,这种说法是不是一种“输家心态”。老黄当场火力全开:
“你面前这个人,不是早上醒来准备输的人。这种输家的态度、输家的假设,对我来说毫无意义。”
最后,老黄平静地总结了自己的核心观点:
“没有人说要么全部开放、要么全封闭。美国必须永远领先,拥有最好的技术。但同时我们也应该积极参与全球竞争并赢下市场。这两件事是完全能同时做到的。世界从来不是非黑即白的。”

【9】收购 Groq 背后:推理市场进入分层时代
访谈最后阶段,Dwarkesh 将话题从敏感的地缘政治拉回到技术上,问老黄:“Nvidia 为什么不尝试不同的芯片架构?比如 Cerebras 那种晶圆级芯片,或者像 Dojo 那样的大封装结构,甚至推出完全不依赖 CUDA 的版本?”
老黄简单又直接地回应:“我们当然能做,但事实证明这些架构并没有更好。它们早就在我们的模拟器里反复验证过了,效果都不如现在的方案。”
不过他承认,Nvidia 最近的确在推理芯片领域迈出了新的一步——高价收购了 Groq。
但老黄强调,收购 Groq 并非因为 GPU 架构不够优秀,而是因为推理市场本身出现了重大变化:
“几年前,推理产生的 Token 基本不值钱,甚至可以说免费。但现在不同客户对 Token 的要求不同,他们愿意为更快的响应速度支付更高的价格。”
他举了自家软件工程师的例子:“如果我们能给工程师提供更快响应的 Token,让他们的生产力翻倍,我们当然愿意为此额外付费。”这就是所谓的“高端推理市场”,过去并不存在,但如今正在快速形成。
老黄继续解释:“我们现在已经进入了一个『推理分层时代』。同一个模型可以根据响应速度不同来定价,这意味着吞吐量高不再是唯一标准。更快的响应速度,即使整体吞吐量低一些,也可能获得更高的平均售价(ASP)。”
对于是否会考虑回到旧制程(比如 7nm)来缓解芯片供应压力的问题,老黄果断表示不太可能:
“理论上可以这么做,但经济上完全不划算。我们能承担得起向前发展,但负担不起向后退步。每一代新架构的进步,不仅仅是制程,还有封装、堆叠技术、数值精度和整体系统架构的革新。除非有一天真的再也无法提高产能,否则我们绝不会往回走。”

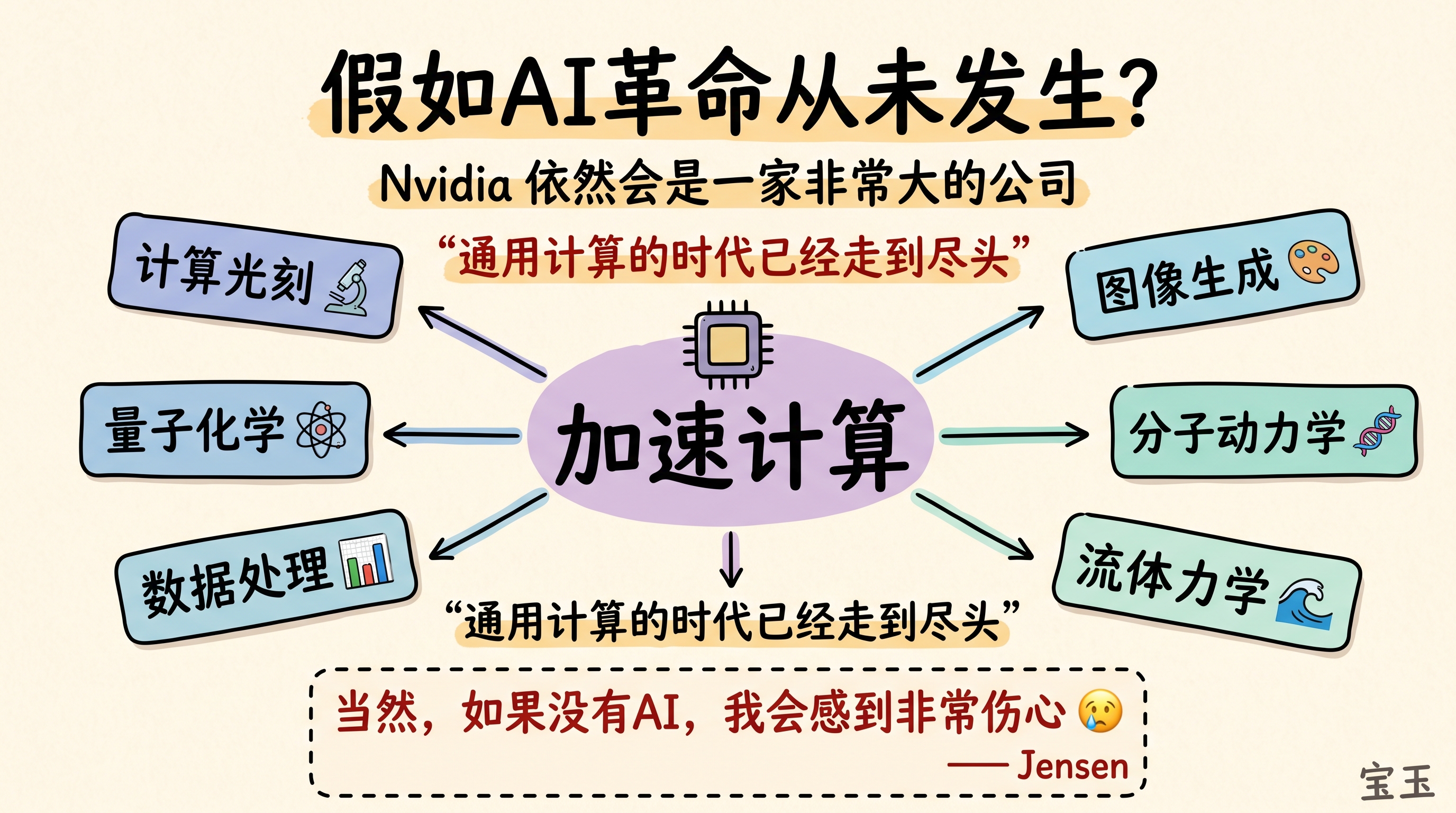
【10】假如 AI 革命从未发生,Nvidia 还会做什么?
访谈的尾声,Dwarkesh 提出了一个假设性的、稍显哲学的问题:“如果深度学习革命从来没有发生,今天的 Nvidia 会做什么?”
老黄没有犹豫,干脆地回答:“我们还是会做加速计算,这本来就是 Nvidia 一直在做的事。”他强调,通用计算的时代已经走到了尽头,计算世界转向加速计算的趋势和 AI 并不必然相关。
“即使 AI 不存在,Nvidia 依然会是一家非常大的公司。”
他说,即便没有 AI,计算光刻、量子化学、数据处理和图像生成等领域,依旧需要强大的加速计算能力。他提到 GTC 大会上有很大一部分话题并非围绕 AI 展开,但依然对产业至关重要。
“张量计算不是计算的全部。我们希望能帮助所有计算领域。”
但老黄最后也坦率承认了自己内心深处的一点小情绪:“但如果世界上真的没有 AI,我会感到非常伤心。”
最后的快问快答
Q:Nvidia 会不会变成商品化公司? Jensen:不会。因为从电子到 Token 的转化本身非常复杂,工程和科学问题还远未被理解透彻。AI 智能体的爆发还会为软件工具带来巨大的需求增长。
Q:CUDA 最大的价值到底是什么? Jensen:不是技术锁定,而是全球数亿块 GPU 的装机量、极其丰富的生态系统,以及跨每一家云平台的便捷性。此外,Nvidia 的工程师还能帮客户轻松实现 2-3 倍的性能提升。
Q:Anthropic 为什么选择 TPU 而不是 GPU? Jensen:因为 Nvidia 早年缺乏财务能力,没有及时投资 Anthropic,导致他们不得不依靠 Google 和 AWS 的芯片生态。这是一个特例,而不是长期趋势。
Q:Nvidia 应不应该向中国出售 AI 芯片? Jensen:应该。中国已经有了充足的 7nm 芯片产能和丰富的能源,出口限制只会加速中国自主生态的建立。美国需要在所有技术层面积极竞争,而不是通过牺牲市场来“赢”。
Q:Nvidia 为什么自己不做云服务? Jensen:“因为如果我们不做,总有人会做。”Nvidia 的哲学是只做那些如果我们不做,就没人能做的事情。而云基础设施显然不属于这一类。
老黄的自相矛盾与现实考验

这场近两个小时的访谈,呈现出了几个值得持续关注的矛盾与悬念。
首先,老黄所谓“尽可能少做事”的哲学,在现实中早已偏离了字面含义。投入 300 亿美元给 OpenAI,100 亿美元给 Anthropic,花 200 亿美元收购 Groq,又扶持 CoreWeave 等新兴云服务商……Nvidia 的触手实际上早已深入 AI 产业链的每一个环节。如今看来,这个原则更像是一种事后美化的叙事,而非真正约束行动的法则。
其次,“Anthropic 是特例”这一论断,能否扛住现实的检验也充满悬念。Anthropic 在过去一年与 Broadcom 和 Google 的 TPU 合作规模翻了数倍(从 1GW 增至 3.5GW),与此同时 OpenAI 也开始发展自己的 Triton 框架并和 AMD 合作。如果未来出现更多这样的“特例”,那么老黄的说法基础势必动摇。
再来看最敏感的对华出口话题。整场辩论下来,老黄始终没有直面回答一个最关键的问题:“他到底愿意接受什么程度的出口限制?”他反复强调不应该限制出口,又同时表示美国必须永远领先。一旦这两种立场发生冲突,究竟哪个更重要?他没有给出明确答案。他举出的“美国电信产业失败”的案例虽有启发性,但这种类比是否能完全适用于 AI 芯片这种显著的双重用途技术,仍有待商榷。
而在商业策略上,老黄一再强调 Nvidia 作为“行业基石”绝不涨价、不搞竞价分配 GPU,能精准预测每年发布新架构。但这个承诺的可信度,很大程度上依赖于 Nvidia 目前超过 70% 的超高毛利率。当竞争真正来临时,Nvidia 是否还能如此慷慨与淡定?
接下来 Vera Rubin 架构的实际量产进度与性能表现、Groq 3 LPX 在真实推理任务中的表现,以及中国自研芯片在未来几个月的真实部署规模,都将是检验老黄此次访谈诸多观点的最佳指标。
完整访谈视频:Dwarkesh Patel Podcast