编程智能体的核心组件【译】
Sebastian Raschka
编程智能体的核心组件【译】
原文:Components of A Coding Agent https://magazine.sebastianraschka.com/p/components-of-a-coding-agent
作者:Sebastian Raschka, 博士
编程智能体如何在实践中利用工具、记忆和代码仓库上下文,让大语言模型发挥更大威力
在这篇文章里,我想和大家聊聊编程智能体(Coding Agent)和 Agent harness(智能体 Harness)的整体设计。它们到底是什么?怎么工作的?在实际应用中,各个部件又是如何协同配合的?因为经常有读者问我关于智能体的问题(他们大多读过我写的《从零构建大语言模型》和《从零构建推理模型》),所以我决定写这篇参考指南,方便以后直接分享给大家。
往大了说,智能体现在之所以这么火,是因为最近实用化大语言模型(LLM)的进步,不仅仅靠模型本身变强,更在于我们怎么用它们。在很多真实的落地场景里,模型外围的配套系统——比如工具调用、上下文管理和记忆功能——发挥的作用一点都不比模型本身小。这就解释了,为什么像 Claude Code 或 Codex 这样的系统,用起来感觉比你在普通聊天界面里直接跟它们背后的模型对话要强得多。
接下来,我将为大家梳理编程智能体的六大核心模块。
Claude Code、Codex CLI 与其他编程智能体
大家可能对 Claude Code 或 Codex CLI(CLI 即命令行界面,一种让用户在终端中通过敲代码输入指令来操作计算机的工具)已经很熟悉了。简单定个基调:它们本质上都是智能体化的编程工具。它们把大语言模型包裹在一个应用层(也就是我们说的 Agent harness)里,从而在处理编程任务时更加顺手,表现也更好。
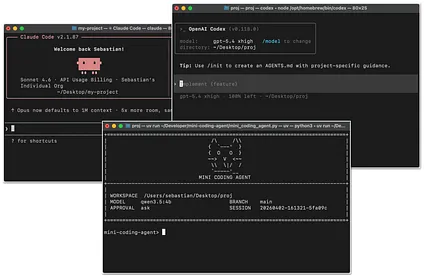
图 1:Claude Code CLI、Codex CLI,以及我自己写的极简版编程智能体。
编程智能体是专门为软件开发打造的。在这里,重头戏可不仅仅是你选了哪个模型,更在于外围的配套系统——包括代码仓库的上下文(Repo Context)、工具的设计、提示词缓存的稳定性、记忆能力,以及能够应对长时间连续工作的连贯性。
弄清楚这个区别很重要。因为当我们聊起“大语言模型的编程能力”时,大家往往会把“模型本身”、“模型的推理行为”和“智能体产品”混为一谈。所以在深入探讨编程智能体细节之前,让我先花点时间,简单梳理一下大语言模型、推理模型和智能体这三个宽泛概念之间的区别。
厘清关系:大语言模型、推理模型与智能体
大语言模型(LLM) 是核心,本质上它就是一个不断预测“下一个词”的模型。推理模型(Reasoning Model) 其实也是 LLM,只不过它经过了特殊的训练或提示词引导,会在生成答案时投入更多的计算力(即增加推理时间的算力消耗,这被称为 test-time compute),用来做中间步骤的推理、自我验证,或者在多个候选答案中搜索最佳结果。
智能体(Agent) 则是盖在模型上面的一层,你可以把它理解为一个围绕模型运转的“控制循环”。通常情况是这样的:你给出一个目标,智能体层(或者说 Harness)就会替模型做决定:接下来要检查什么?该调用哪个工具?怎么更新当前的状态?什么时候算是大功告成可以停下来?
打个不太恰当但很直观的比方:LLM 就像是一台普通的发动机;推理模型是一台经过爆改、马力更强劲的发动机(当然,也更费钱);而 Agent harness,则是帮助我们更好地驾驭这台发动机的整车系统。虽然我们也可以直接在聊天界面或 Python 代码里单拎出 LLM 和推理模型来用,但我希望这个比喻能把它们的关系说明白。
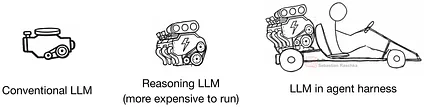
图 2:常规大语言模型、推理大语言模型(或推理模型)与包裹在 Agent harness 中的大语言模型之间的关系。
换句话说,智能体就是一个在特定环境里不断循环调用模型的系统。
总结一下:
- 大语言模型 (LLM): 最原始的基础模型。
- 推理模型 (Reasoning model): 优化过的 LLM,专门为了输出中间推理过程(也就是我们常说的思维链 Chain of Thought)和增强自我验证能力。
- 智能体 (Agent): 一个包含了“模型 + 工具 + 记忆 + 环境反馈”的循环系统。
- Agent harness (智能体运行框架): 围绕智能体搭建的软件脚手架,负责管理上下文、工具调用、提示词、状态和控制流。
- Coding harness (编程运行框架): Agent harness 的“特化版”,专门针对软件工程量身定制,负责管理代码上下文、开发工具、代码执行和迭代反馈。
就像上面列出的,在讨论智能体和编程工具时,我们常会碰到这两个词:Agent harness(智能体运行框架) 和 Coding harness(编程运行框架)。Coding harness 是帮助模型高效编写和修改代码的软件脚手架。而 Agent harness 的适用面更广,不仅限于编程(比如 OpenClaw)。Codex 和 Claude Code 都可以算作 Coding harness。
总而言之:更好的 LLM 能为推理模型打下更坚实的基础(当然还需要额外的训练),而优秀的 Harness 则能把推理模型的潜力压榨到极致。
当然,LLM 和推理模型光靠自己(不用任何 Harness)也能解决一些编程问题。但是,真实的写代码可不仅仅是“预测下一个词”。开发工作中有很大一部分精力耗费在浏览代码仓库、搜索文档、查找函数、应用代码差异(Diff)、跑测试、排查报错,以及在脑子里把所有这些信息串联起来。(程序员朋友们肯定深有体会,这绝对是个极其耗费心神的脑力活,这也是为什么大家在专注敲代码时最讨厌被打断 :))。
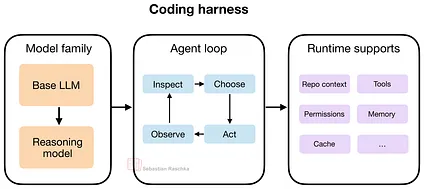
图 3:一个 Coding harness 融合了三层结构:模型家族、智能体循环以及运行时支撑。模型提供了“发动机”,智能体循环驱动迭代式的解题过程,而运行时支撑则提供了必要的基础管道。在这个循环里,“观察”负责从环境收集情报,“审查”负责分析这些情报,“选择”决定下一步该怎么走,“执行”则负责落地行动。
这里的核心要点是:一个优秀的 Coding harness,能让模型(无论是不是推理模型)用起来感觉比在简陋的聊天框里强大无数倍,因为它帮你把上下文管理等脏活累活全干了。
Coding harness:模型的超级外挂
就像刚才提到的,当我们说“Harness(运行框架)”时,通常指的是包裹在模型外面的那一层软件。它简直是个全能管家,负责拼接提示词、提供工具、追踪文件状态、修改代码、执行命令、管理权限、缓存那些不变的提示词前缀,还要负责存储记忆等等。
今天,当你使用大模型时,你的绝大部分体验,都是由这一层 Harness 决定的。这跟直接去提示(Prompt)模型,或者用普通的网页聊天界面(那种更像是“上传个文件然后跟它尬聊”)有着天壤之别。
在我看来,现在的原味基础版大模型(比如 GPT-5.4、Opus 4.6 和 GLM-5 的基础版),它们的能力其实已经非常接近了。在这个阶段,真正拉开差距、让某个模型显得更好用的决定性因素,往往就是这个外围 Harness。
这里我大胆猜测一下:如果我们把最新、最强的开源模型(比如 GLM-5)塞进一个同样优秀的 Harness 里,它的表现很可能跟 Codex 里的 GPT-5.4 或者 Claude Code 里的 Claude Opus 4.6 不相上下。话虽如此,专门为了适配 Harness 做一些后训练(Post-training)肯定还是有好处的。比如,OpenAI 过去就会专门维护 GPT-5.3 和专门写代码的 GPT-5.3-Codex 两个不同的版本。
在下一节,我将用我手搓的一个开源项目“迷你编程智能体(Mini Coding Agent)”为例,带大家深入了解 Coding harness 的具体细节和核心组件。项目地址:https://github.com/rasbt/mini-coding-agent。
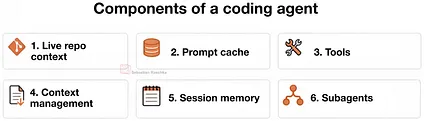
图 4:将在后续章节中探讨的编程智能体/Coding harness 的核心功能模块。
顺便提一句,为了阅读流畅,本文中我会交替使用“编程智能体”和“Coding harness”这两个词。(严格来说,智能体是由模型驱动的决策循环,而 Harness 是提供上下文、工具和执行环境的外围软件脚手架。)
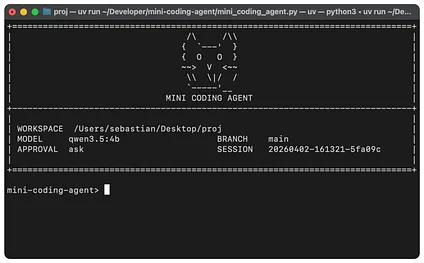
图 5:极简但五脏俱全、纯手工打造的 Mini Coding Agent(纯 Python 实现)。
废话不多说,下面就是编程智能体的六大核心组件。如果你想看具体的代码实现,可以去翻翻我用纯 Python 从头编写的 Mini Coding Agent。代码里也用注释标出了这六大组件:
##############################
#### 六大智能体组件 ####
##############################
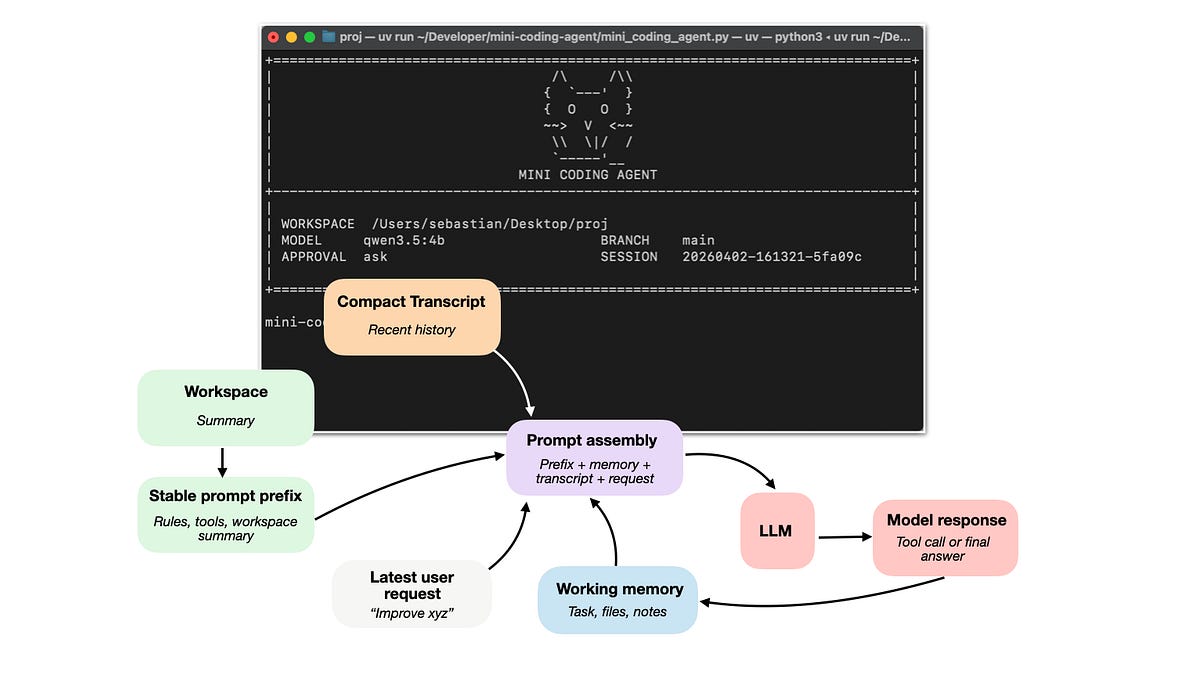
# 1) 实时代码仓库上下文 -> WorkspaceContext
# 2) 提示词形态与缓存复用 -> build_prefix, memory_text, prompt
# 3) 结构化工具、验证与权限 -> build_tools, run_tool, validate_tool, approve, parse, path, tool_*
# 4) 上下文瘦身与输出管理 -> clip, history_text
# 5) 完整对话记录、记忆与恢复 -> SessionStore, record, note_tool, ask, reset
# 6) 任务委派与受限子智能体 -> tool_delegate
1. 实时代码仓库上下文 (Live Repo Context)
这可能是最显而易见的一个组件,但也绝对是最关键的之一。
当用户下达命令“把测试代码修一下”或者“实现 xyz 功能”时,模型不能两眼一抹黑。它得知道自己是不是在一个 Git 代码库里、当前在哪个分支上、项目的哪些文档里可能藏着开发规范等等。
为什么呢?因为这些细节直接决定了模型该采取什么行动。“修测试”这句话本身信息量是不够的。如果智能体能看到 AGENTS.md 或者项目的 README 文件,它就能学到该运行哪条具体的测试命令。如果它了解代码库的根目录和文件结构,它就能有的放矢地去对的地方找代码,而不是瞎猜。
另外,Git 的分支、状态和提交记录(Commits)也能提供丰富的背景信息,告诉模型当前正在做哪些修改、重点应该放在哪里。
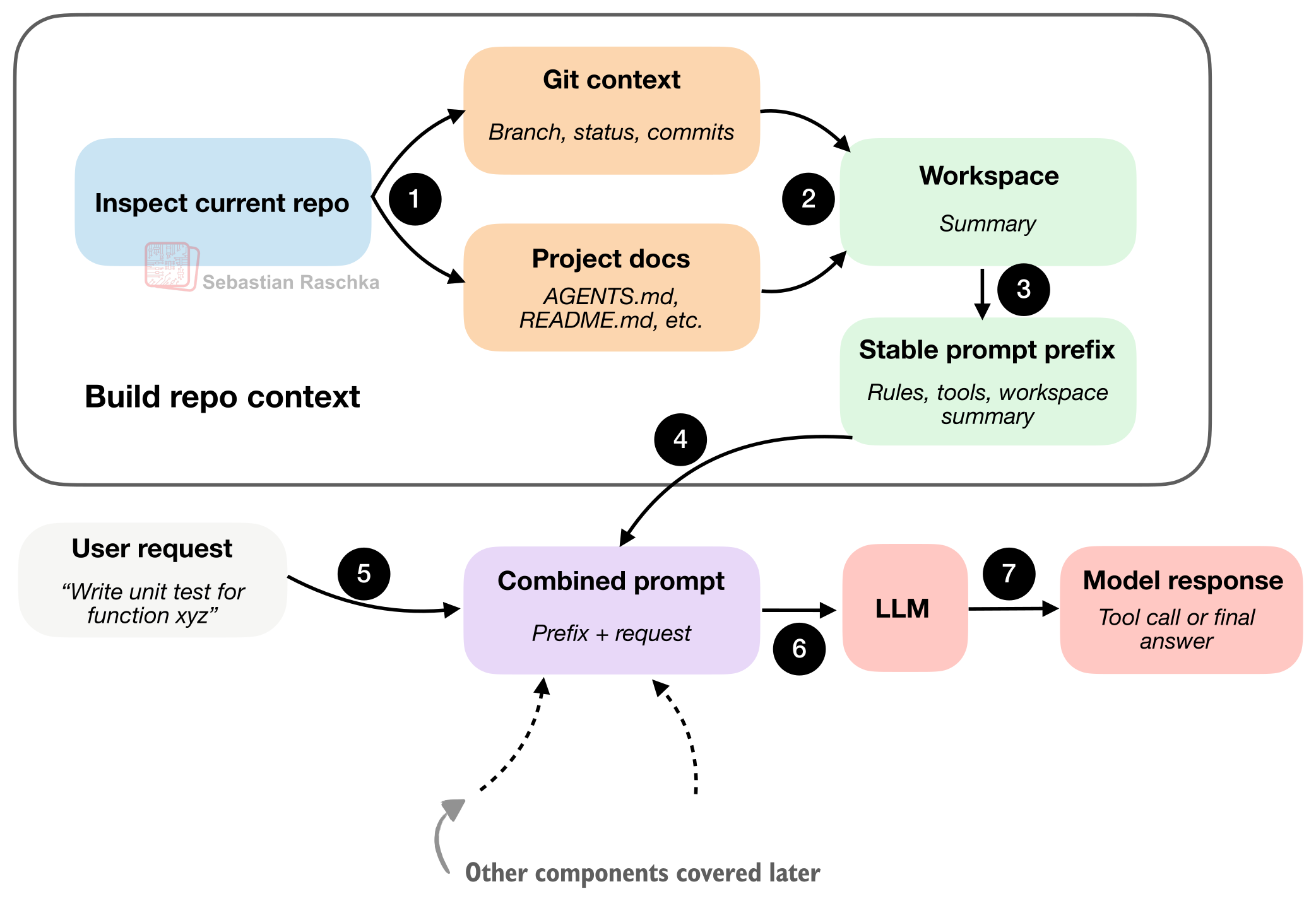 图 6:Coding harness 首先会生成一份简短的工作区摘要,并将其与用户的请求合并,从而为模型提供更多的项目上下文。
图 6:Coding harness 首先会生成一份简短的工作区摘要,并将其与用户的请求合并,从而为模型提供更多的项目上下文。
所以这里的精髓在于:在动手干活之前,编程智能体会先去收集情报(把这些“稳定的事实”打包成一份工作区摘要)。这样一来,在面对你的每一次提示时,它都不是在没有任何上下文的“零基础”状态下盲目启动。
2. 提示词形态与缓存复用 (Prompt Shape And Cache Reuse)
智能体摸清了代码库的底细后,下一个问题来了:怎么把这些信息喂给模型?上一节的示意图给了一个极其简化的说法(“合并提示词:前缀 + 请求”)。但在实操中,如果每一次用户提问,都要把一大坨工作区摘要重新拼凑、让模型重新阅读一遍,那绝对是巨大的算力浪费。
写代码是一个反复拉扯的过程。在这个过程中,智能体的行为准则通常是不变的,工具的说明书是不变的,甚至连工作区摘要在大部分时间里也是基本不变的。真正频繁变动的是什么?是你最新发出的指令、刚刚产生的对话记录,以及一些短期记忆。
一个“聪明”的 Harness,绝对不会在每一轮对话时,都把所有东西揉成一团巨大的提示词重新扔给模型。这就如下图所示:
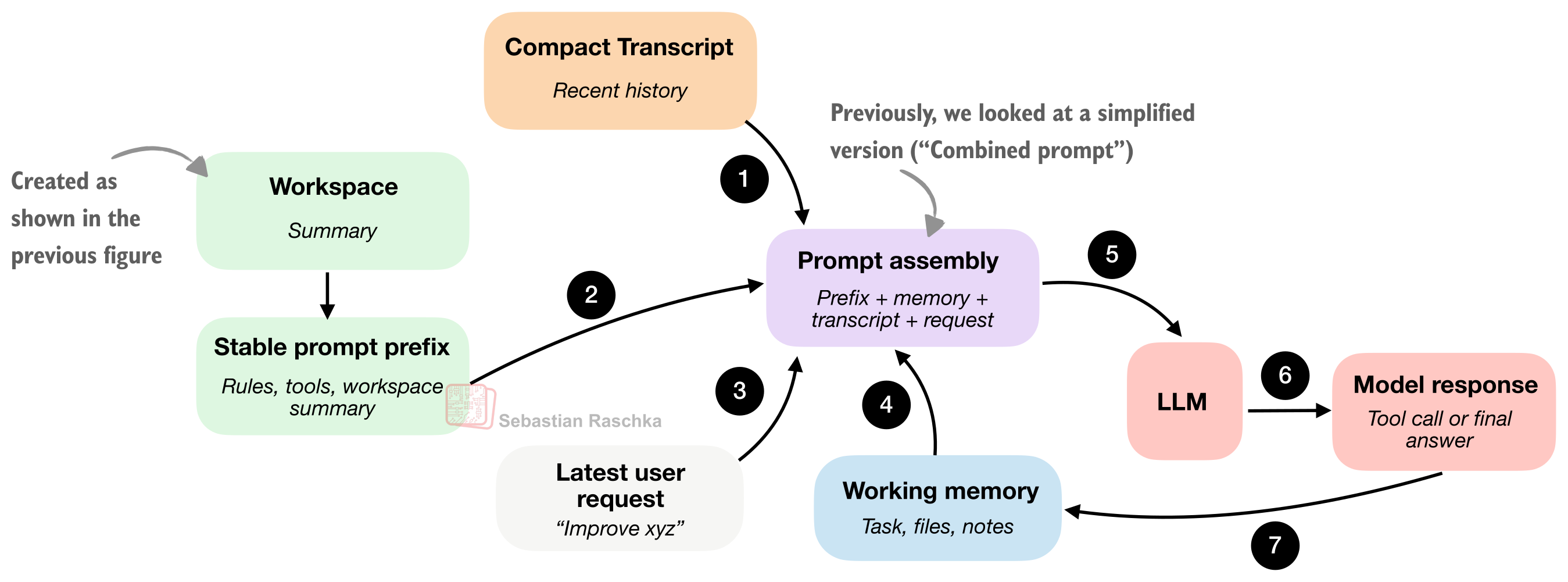 图 7:Coding harness 会构建一个稳定的提示词前缀,拼上不断变化的会话状态,然后把这份合并后的提示词喂给模型。
图 7:Coding harness 会构建一个稳定的提示词前缀,拼上不断变化的会话状态,然后把这份合并后的提示词喂给模型。
和第 1 节不同:第 1 节讲的是如何收集代码库的情报;而这一节关注的是,如何把这些情报高效地打包和缓存起来,方便模型在无数次调用中反复使用。
所谓的“稳定的提示词前缀”,意思是这里面的信息变动极小。它通常包含了通用的系统指令、工具的说明以及工作区摘要。只要没有发生伤筋动骨的变化,我们就绝不浪费算力去每次从头重建这部分内容(现在主流的大模型 API 都支持了 Prompt Cache,即提示词缓存机制,可以大幅省钱和提升响应速度)。
那些需要频繁更新的组件(通常每轮对话都要变),则包括短期记忆、近期的对话记录,以及用户最新的需求。
简而言之,聪明的 Harness 会尽可能地把“稳定的提示词前缀”缓存起来重复利用。
3. 工具的接入与调用 (Tool Access and Use)
一旦涉及到工具的接入和调用,这就开始脱离“单纯聊天”的范畴,真正有了“智能体”的内味儿了。
普通模型只能用文字大段大段地建议你“应该怎么做”;但装在 Coding harness 里的 LLM,动作要精准、实用得多。它能够实打实地去执行命令,并自己把运行结果取回来分析(再也不用我们手动复制命令去终端跑,然后再把报错信息粘贴回聊天框了)。
不过,Harness 可不会任由模型放飞自我地乱写一通。通常,Harness 会提供一份预先定义好的“白名单工具箱”,每个工具都有名字、明确的输入要求和严格的边界。(当然,你也可以把类似 Python 的 subprocess.call 塞进工具箱,这样智能体就能执行极其广泛的终端命令了。)
工具调用的完整流程如下:
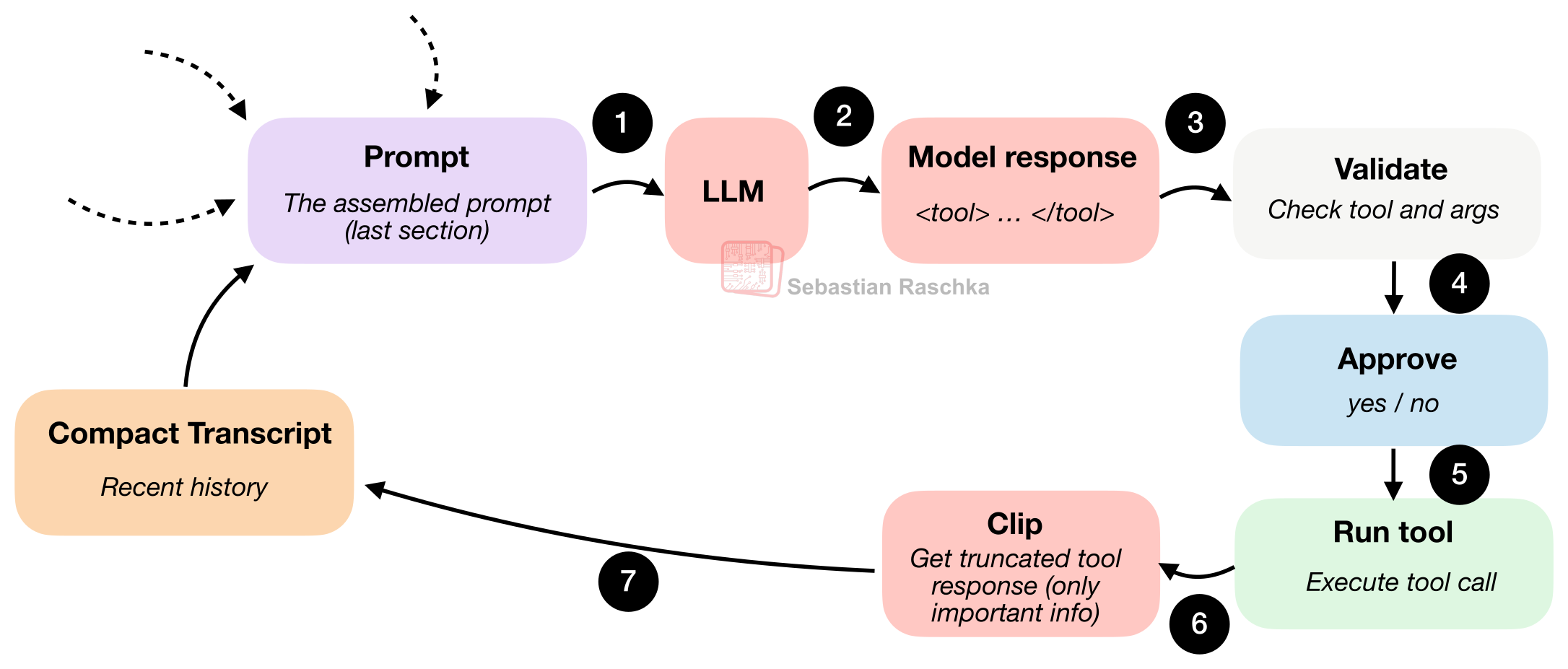 图 8:模型输出一个结构化的动作,Harness 对其进行验证(需要的话还会请求人工批准),然后执行该动作,最后把受控的执行结果传回给循环系统。
图 8:模型输出一个结构化的动作,Harness 对其进行验证(需要的话还会请求人工批准),然后执行该动作,最后把受控的执行结果传回给循环系统。
为了更直观,我用我的 Mini Coding Agent 跑了个例子给大家看。在用户视角下,它是长这样的。(界面虽然没有 Claude Code 或 Codex 那么炫酷,毕竟它是用纯 Python 写的极简版本,没有任何外部依赖。)
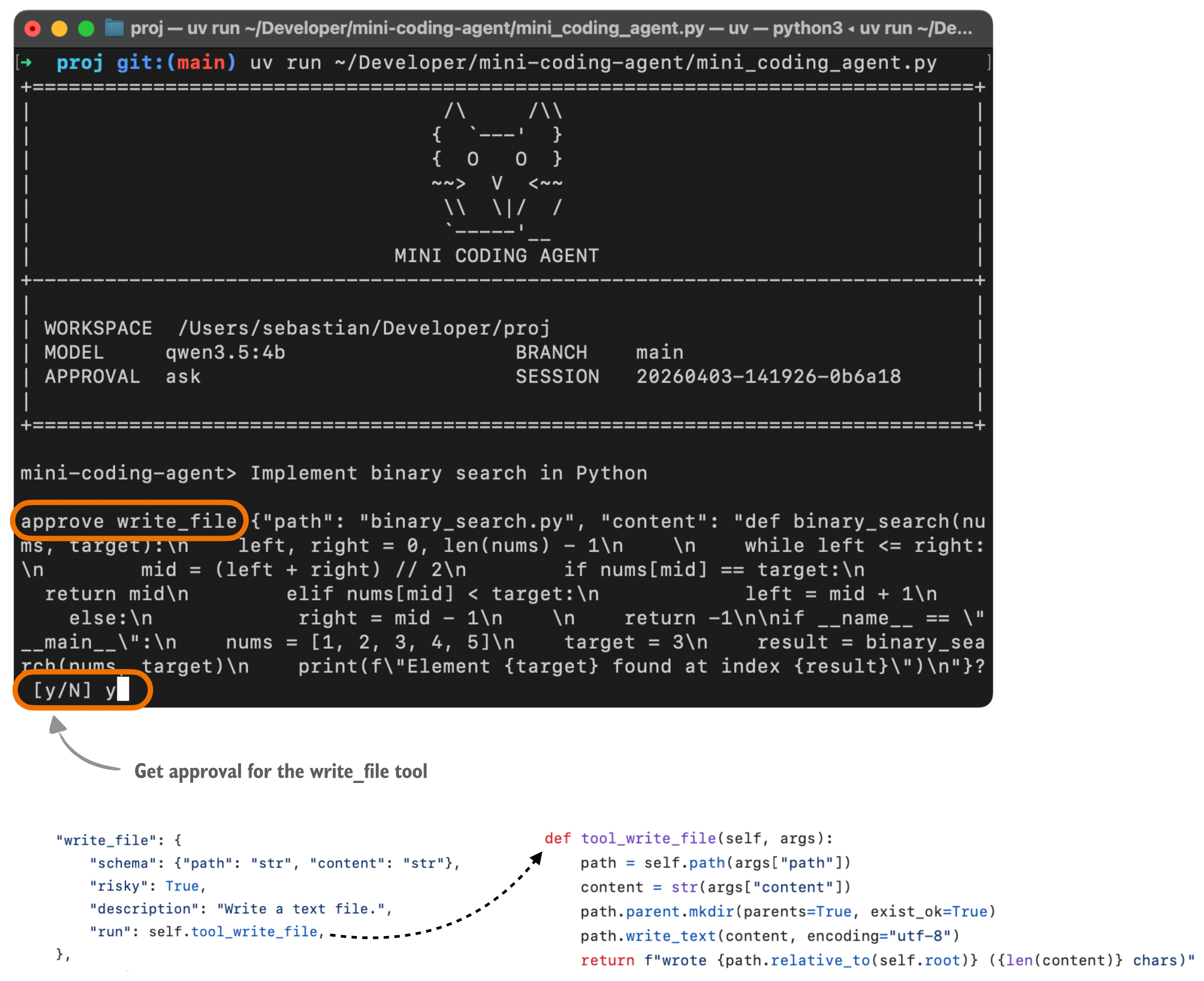 图 9:Mini Coding Agent 弹出工具调用审批请求的界面示例。
图 9:Mini Coding Agent 弹出工具调用审批请求的界面示例。
在这个环节,模型必须从 Harness 认识的动作里挑一个,比如:列出目录文件、读取文件、全局搜索、运行 Shell 命令、写入文件等。同时,它提供参数的格式也必须规规矩矩,方便 Harness 进行拦截校验。
所以,每当模型试图动手干点什么时,运行环境就能立刻按暂停,并通过代码进行“安检”:
- “这是一个已知的工具吗?”
- “参数合法吗?”
- “这个高危操作需要用户手动批准吗?”
- “你要访问的文件路径,超出当前代码仓库的范围了吗?”
只有这些安检全部绿灯,命令才会被真正执行。虽说让智能体自己跑代码肯定有风险,但正是有了 Harness 的重重把关,确保模型不会瞎跑高危命令,整个系统的可靠性才得以大幅提升。
另外,除了拦截格式错误的动作和引入人工审批,Harness 还能通过卡死文件路径,把模型的操作死死限制在代码仓库的范围内。从某种意义上说,Harness 确实剥夺了模型的一部分“自由”,但这也换来了极大的安全性和实用性。
4. 给上下文瘦身,防止撑爆 (Minimizing Context Bloat)
“上下文膨胀(Context Bloat)”并不是编程智能体独有的烦恼,它是所有大模型共同的痛点。确实,现在的 LLM 支持的上下文越来越长(我最近刚写过一篇关于注意力机制变体如何降低计算成本的文章),但是长上下文依然很费钱,而且如果里面混入了大量无关信息,还会给模型带来严重的噪音干扰。
在多轮对话中,编程智能体比普通的 LLM 聊天更容易“吃撑”。因为它们会频繁地读取文件,而工具输出和日志信息往往又臭又长。
如果 Harness 老老实实地把所有细节一字不落地存下来,可用的 Token 额度瞬间就会被榨干。因此,一个优秀的 Coding harness,在处理上下文瘦身这方面通常非常硬核,绝对不是像普通聊天软件那样简单粗暴地裁剪或总结一下就完事了。
概念上,编程智能体的上下文压缩机制可以总结为下图。简单来说,这是对上一节图 8 中“裁剪(clip,步骤 6)”环节的放大特写。
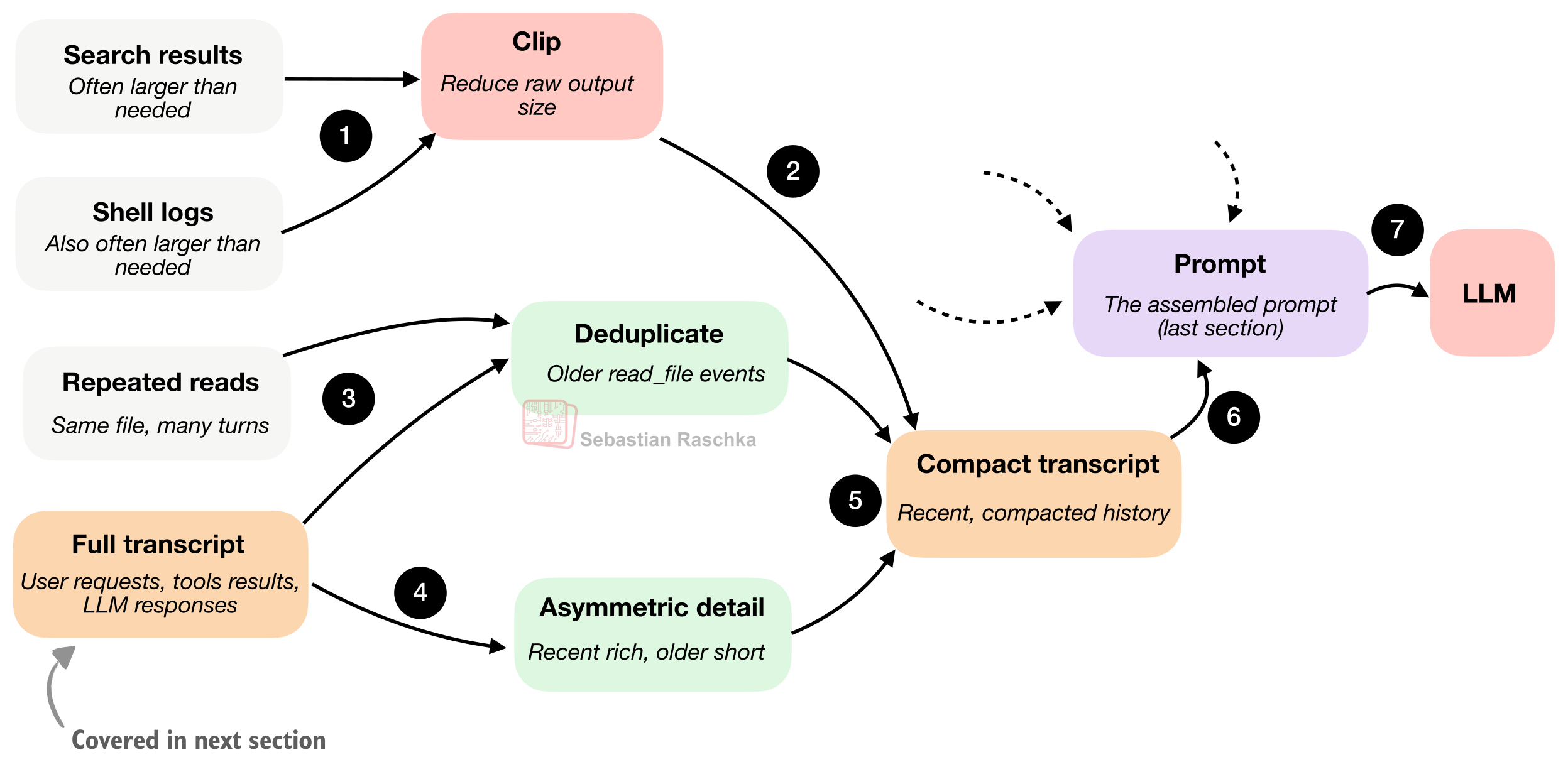 图 10:超长的输出会被暴力裁剪,早期读取的重复文件会被剔除,而完整的对话记录在重新塞入提示词之前会被大幅压缩。
图 10:超长的输出会被暴力裁剪,早期读取的重复文件会被剔除,而完整的对话记录在重新塞入提示词之前会被大幅压缩。
一个及格的极简 Harness,至少会用两招来对付这个问题。
第一招是裁剪(Clipping)。面对长篇大论的文档片段、海量的工具输出日志、备忘录以及长对话,它会毫不留情地截断。换句话说,绝不能让某一段废话因为“碰巧比较长”,就挤占了整个提示词的预算。
第二招是对话记录精简或总结(Transcript reduction/summarization)。它会把完整的历史记录(下一节会详细讲)提炼成一份轻量级的、方便放入提示词的摘要。
这里的核心秘诀是:越近的事情,保留的细节越多,因为它们往往对当下的决策最关键;越久远的事情,压缩得越狠,因为它们的参考价值已经没那么大了。
此外,我们还要对早期读取的文件做去重处理。不能因为智能体在几轮对话前反复查看了某个文件,就让模型一遍遍地在上下文里看到同样的文件内容。
总的来说,我认为这部分是优秀的编程智能体设计中,最被低估、也最枯燥的环节。我们平时夸赞的所谓“这个模型真聪明”,很大程度上其实归功于“这个系统喂给它的上下文质量真高”。
5. 结构化的会话记忆 (Structured Session Memory)
在实操中,本文提到的这 6 个核心概念是紧密交织在一起的,不同的章节和配图只是侧重点和放大倍数不同。在上一节中,我们探讨了在“构建提示词时”如何利用历史记录,以及如何打造精简版对话。那一节的核心问题是:在下一轮对话中,应该把多少历史包袱塞回给模型?所以重点在于压缩、裁剪、去重和近期优先。
而现在这一节“结构化的会话记忆”,讲的是在“硬盘存储时”历史记录该长什么样。这里的核心问题变成了:智能体该长期保存哪些数据作为永久档案?这里的重点是:运行环境不仅要保存一份巨细无靡的“完整对话记录”作为持久状态,还要维护一个更轻量级的“记忆层”。这个记忆层很小,并且它是被不断修改和提炼的,而不是像流水账那样一味地只增不减。
总结一下,编程智能体会把状态(至少)分为两层:
- 工作记忆(Working memory): 小巧而纯粹,是智能体刻意单独维护的核心状态。
- 完整记录(Full transcript): 涵盖了用户的所有请求、所有工具的输出日志,以及 LLM 的每一次回答。
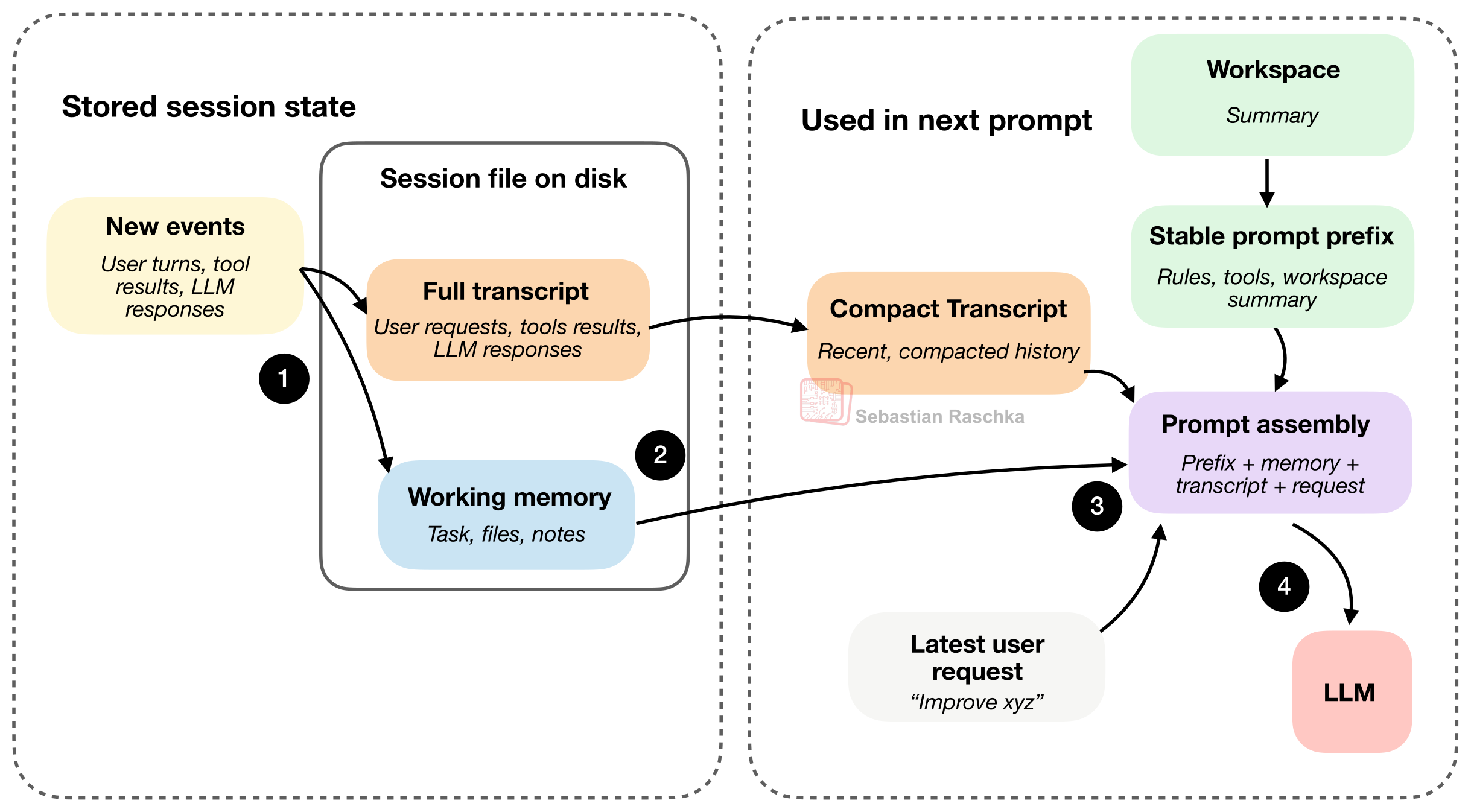 图 11:产生的新事件会被追加到完整记录中,同时其核心信息会被总结进工作记忆里。硬盘上保存的会话文件通常是 JSON 格式。
图 11:产生的新事件会被追加到完整记录中,同时其核心信息会被总结进工作记忆里。硬盘上保存的会话文件通常是 JSON 格式。
上图展示了这两个主要的会话文件,它们通常以 JSON 格式躺在你的硬盘里。如前所述,完整记录保存了事无巨细的所有历史,就算你把智能体关了,下次打开依然能无缝恢复。而工作记忆则是提纯后的精华,只留当下最要紧的信息(这跟前面提到的“精简版对话”有点像)。
但是,“精简版对话”和“工作记忆”分工还是有微妙区别的。精简版对话是为了重组提示词服务的,它的使命是给模型一个近期历史的压缩包,让它不用看完整部《资治通鉴》也能接着往下聊。而工作记忆是为了保持任务连贯性服务的。它的使命是在多轮对话中,手动维护一个包含了核心关键点的小备忘录——比如现在的首要任务是什么、哪些文件最核心、刚刚做过的关键笔记等。
顺着上图的第 4 步往下看,最新的用户请求、LLM 的回复以及工具的输出,会在下一回合作为“新事件”同时记录到完整记录和工作记忆中(为了不让图片显得太乱,这一步在图里省略了)。
6. 任务委派与受限子智能体 (Delegation With (Bounded) Subagents)
当智能体装备了工具,又有了记忆状态,接下来最顺理成章的高阶能力就是:摇人(任务委派)。
为什么需要这个?因为它能把某些脏活累活拆成子任务,分给“小弟(子智能体)”去并行处理,从而大幅加快主线任务的进度。举个例子,主智能体正干着大活,突然需要查个资料:这个变量是在哪个文件里定义的?配置文件里写了啥?或者这个测试为啥挂了?这时候,把这些岔开的疑问剥离出来,交给一个有明确边界的子任务去查,绝对比逼着主智能体一个脑子同时处理所有线索要高效得多。
(在我的 Mini Coding Agent 里,实现方式比较简陋,小弟还是同步串行工作的,但背后的核心思想是一脉相承的。)
不过,要想让子智能体干出点成绩,就得给它传承足够的上下文。但麻烦在于,如果不加以限制,你很快就会看到一群智能体在里面无序繁殖:它们重复做同一件事、抢着修改同一个文件,甚至子智能体又生出孙子智能体,直接乱套。
所以,这里最考验设计的难点,不仅仅是怎么“生”出一个子智能体,更在于怎么给它套上“紧箍咒” :)。
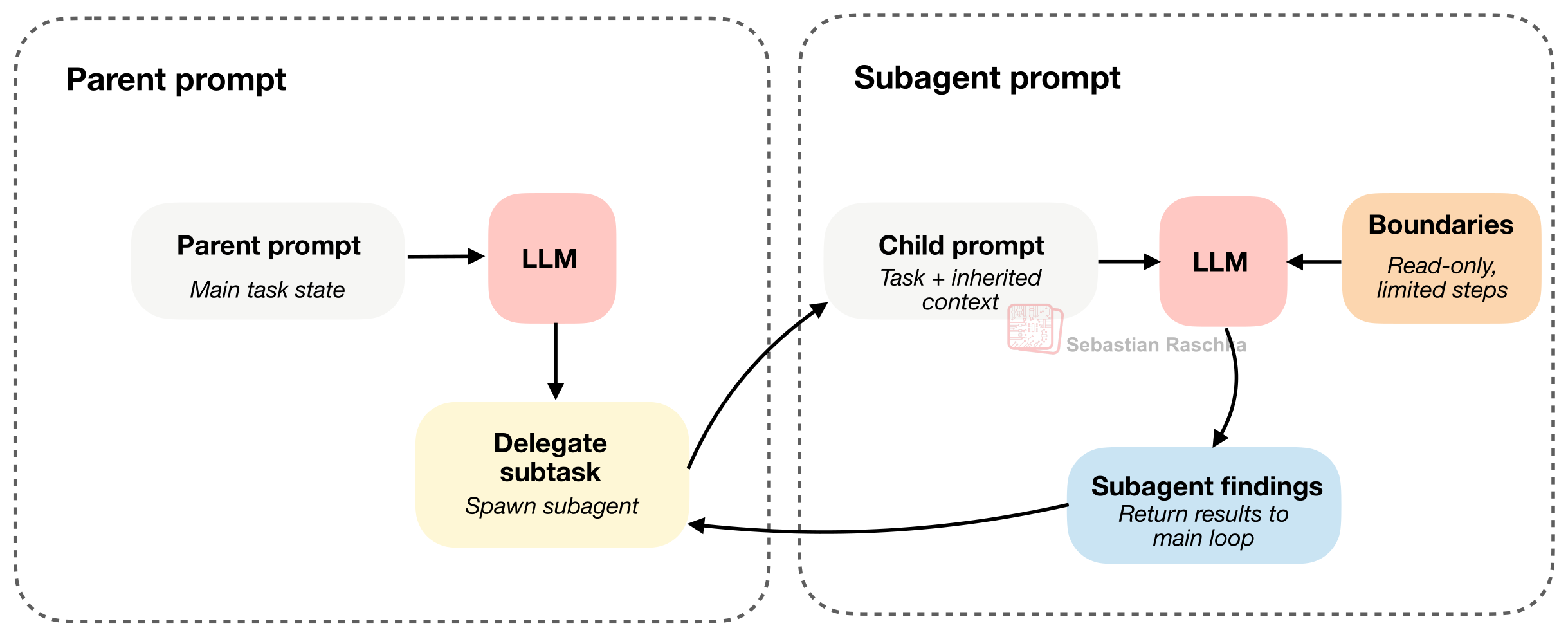 图 12:子智能体继承了足以干活的上下文,但它的运行边界比主智能体要严格得多。
图 12:子智能体继承了足以干活的上下文,但它的运行边界比主智能体要严格得多。
这里的精妙之处在于:子智能体既要继承足够的上下文以便干活,又必须受到严格的约束(比如:只能只读访问文件,绝不允许乱改代码;并且限制它再往下摇人的深度,防止无限递归)。
Claude Code 很早之前就支持子智能体了,Codex 最近也补上了这个功能。有意思的是,Codex 通常不会一刀切地强迫子智能体进入“只读模式”。相反,它们一般会继承主智能体的沙箱环境和审批权限。所以,Codex 给小弟画的圈,更多是限制在任务范围、上下文大小和执行深度上。
组件总结
上面的内容尽量涵盖了编程智能体的所有核心组件。就像之前说的,在真正的代码实现里,它们其实是盘根错节、深度交织的。不过,我还是希望通过这种抽丝剥茧的拆解,能帮你建立起一个全局的心智模型:深刻理解 Coding harness 到底是怎么运作的,以及为什么有了它,大语言模型会比以前那个干巴巴的多轮聊天机器人好用无数倍。
 图 13:前面各节讨论的 Coding harness 的六大核心功能。
图 13:前面各节讨论的 Coding harness 的六大核心功能。
如果你手痒了,想看用极其干净、极简的 Python 代码是怎么实现这些概念的,强烈建议去逛逛我的 Mini Coding Agent。
这和 OpenClaw 比起来有啥区别?
拿 OpenClaw 来做对比挺有意思的,但它们其实并不是同一种类型的系统。
OpenClaw 更像是一个本地运行的通用智能体平台(只是恰好它也能写代码),而不是一个像我们在终端里专用的纯血编程助手。
当然,它跟我们讨论的 Coding harness 还是有不少重合点的:
- 它也会利用工作区里的提示词和指令文件,比如
AGENTS.md、SOUL.md和TOOLS.md。 - 它也用 JSONL 格式保存会话文件,同样支持对话记录压缩和会话管理。
- 它也能召唤小弟(创建助手会话和子智能体)。
- 诸如此类。
但是,如前所述,两者的重心截然不同。编程智能体是专门为了趴在代码库里干活的人而极致优化的,它唯一的追求就是高效地帮你检查文件、修改代码、在本地跑工具。而 OpenClaw 优化的方向是:在多个聊天框、频道和工作区里,同时养着一群长期存活的本地智能体——对 OpenClaw 来说,写代码只是这群智能体的众多日常打卡工作之一。
顺便跟大家分享一个好消息:我的新书《从零构建推理模型》(Build A Reasoning Model (From Scratch))终于杀青啦!所有章节目前都开放了抢先体验(Early access)。出版社正在爆肝排版,预计今年夏天就能正式上市。
这可能是我迄今为止野心最大的一本书。我整整肝了 1.5 年,在里面塞进了无数的实验。无论是投入的时间、精力还是打磨的程度,这都是我倾注心血最多的一部作品,真心希望大家能喜欢。
在 Manning 和亚马逊上可以找到《从零构建推理模型》。
本书的核心干货包括:
- 评估推理模型
- 推理时算力扩展(Inference-time scaling)
- 自我反思与优化(Self-refinement)
- 强化学习(Reinforcement learning)
- 模型蒸馏(Distillation)
现在圈内都在热炒 LLM 的“推理(Reasoning)”能力。而在我看来,要想真正搞懂 LLM 语境下的“推理”到底是个什么鬼,最硬核、最透彻的办法就是——从零开始,亲手敲代码搓一个出来!
- Amazon 亚马逊 (可预购)
- Manning 出版社 (抢先体验版已包含完整内容,排版正在收尾,共 528 页)
来源:https://magazine.sebastianraschka.com/p/components-of-a-coding-agent