AI 辅助编程的质量,关键在于如何管理“工作单元”
作者:Atharva Raykar
阅读 Atharva 的更多文章,请点击这里
AI 辅助软件开发这门手艺,其精髓其实在于如何正确地管理“工作单元”。
刚接触 AI 辅助编程这门新兴手艺时,尽管模型相当智能,我得到的结果却总是一塌糊涂。后来我才发现,主要的瓶颈并非模型不够聪明,而在于没能提供正确的上下文。
Andrej Karpathy 在引用我之前关于这个主题的文章时,将 AI 辅助工程的工作描述为“给 AI 系上一根短缰绳”。在一个 AI 智能体 (AI Agent) 比以往任何时候都更加独立地操作你的代码的流程中,这根“短缰绳”究竟是什么样的呢?他给了一个提示:把工作拆分成一个个具体的、小块的东西来做。
大小合适的工作单元,懂得尊重上下文
我喜欢“上下文工程” (context engineering) 这个词,因为它为我们提供了一套新的词汇,能更好地解释为什么管理工作单元或许是从 AI 工具中获得更佳结果的最重要技巧。它让我们把讨论的焦点放在了 AI 生成代码时所依赖的那块“画布”上。
我很喜欢 Anthropic 在他们文档里的一张图:
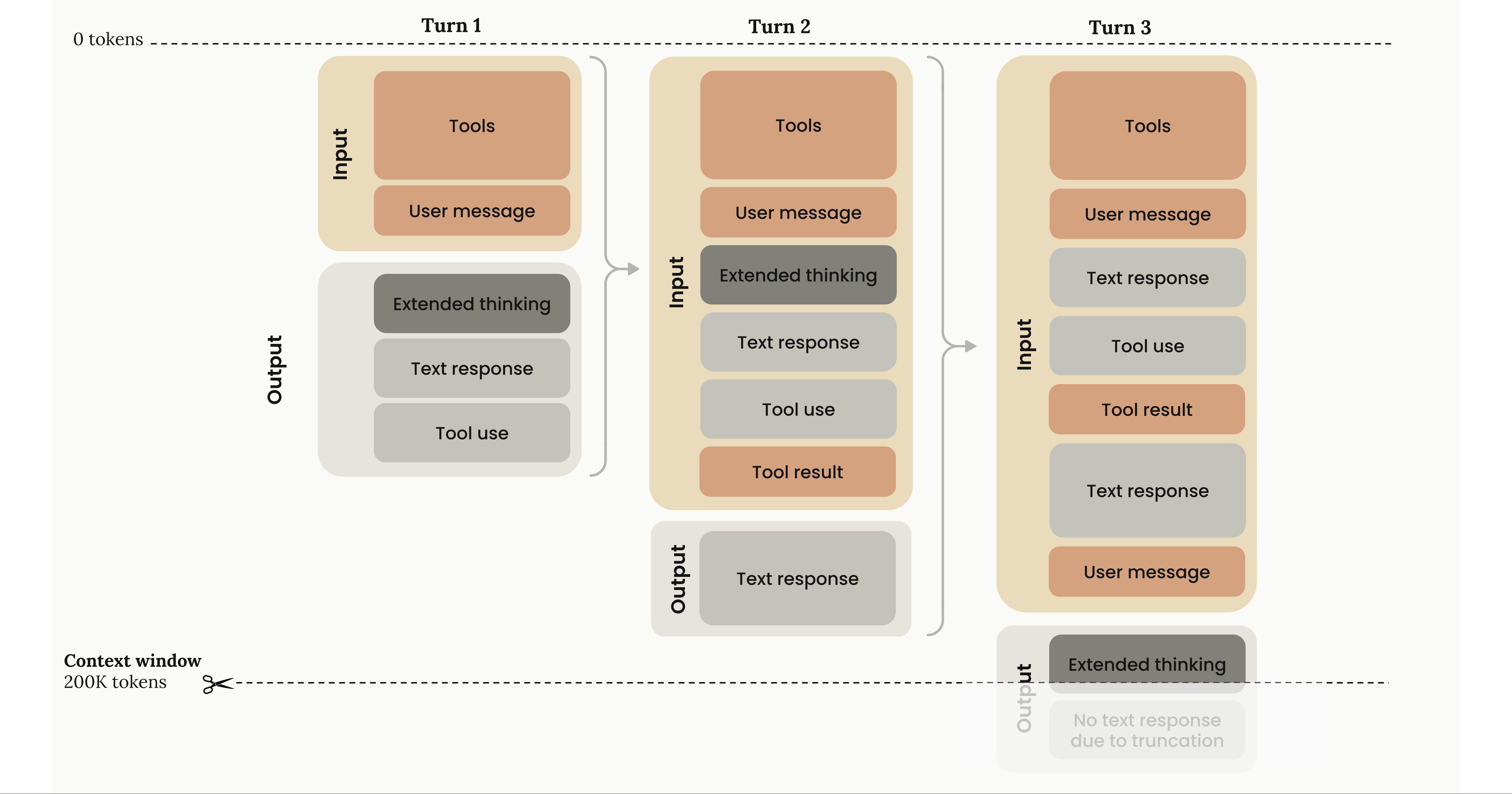
大语言模型 (LLM) 的输出是基于概率生成的下一个词元 (token)。每生成一个词元,之前已经生成的内容就会被追加到上下文窗口中。这个上下文窗口的内容,对最终生成结果的质量有着巨大的影响。
Drew Breunig 写了一篇很棒的文章,探讨了上下文中可能出现的各种问题,并提出了多种修复技巧。
最优秀的 AI 辅助编程工匠,常常在思考如何设计和安排上下文,好让 AI 一次性给出完美的解决方案。这其实非常棘手,也很费力,和那些 AI 编程天花乱坠的宣传完全不是一回事。
如果你没能在上下文中提供必要的信息,AI 就会“胡说八道” (hallucinate),或者生成的代码与你代码库的实践格格不入。在软件系统的集成点上,这个问题尤其脆弱。
反过来说,如果你用太多信息把上下文塞得满满当当,由于注意力不够集中,输出的质量反而会下降。
将任务分解成“大小合适”的工作单元,并为每个单元提供恰到好处的细节,这或许是改善上下文窗口、进而提升生成代码正确性和质量的最强杠杆。
我们来简单算笔账。
假设你的 AI 智能体有 5% 的概率犯错。我这里说的不仅仅是“胡说八道”——也可能是一些细微的错误,比如它忘了查阅某个文档,或者你在需求里漏掉了一个细节。
在一个智能体多轮交互的工作流中(所有编程工作流都在朝这个方向发展),这种错误是会累积的。如果你的任务需要 10 步才能完成,那么你最终成功的概率只有 (1 – 0.95) 10 = 59.9%。这可不算高。
Utkarsh Kanwat 在他的博客文章中也提出了同样的论点。他的结论是,任何 AI 智能体在执行长周期任务时,都需要在每一步设置某种“暂停-验证”的门控机制。
那么,目前最先进的多步任务错误率表现如何呢?METR 最近发布了一张很火的图表,描述了 AI 模型在处理长周期任务方面正变得越来越好。目前 GPT-5 在排行榜上名列前茅,它能以大约 70% 的成功率执行约 2 小时长的任务。反向推算一下(假设一个 2 小时的任务包含 50 多个步骤),这相当于每一步的错误率低于 1%。
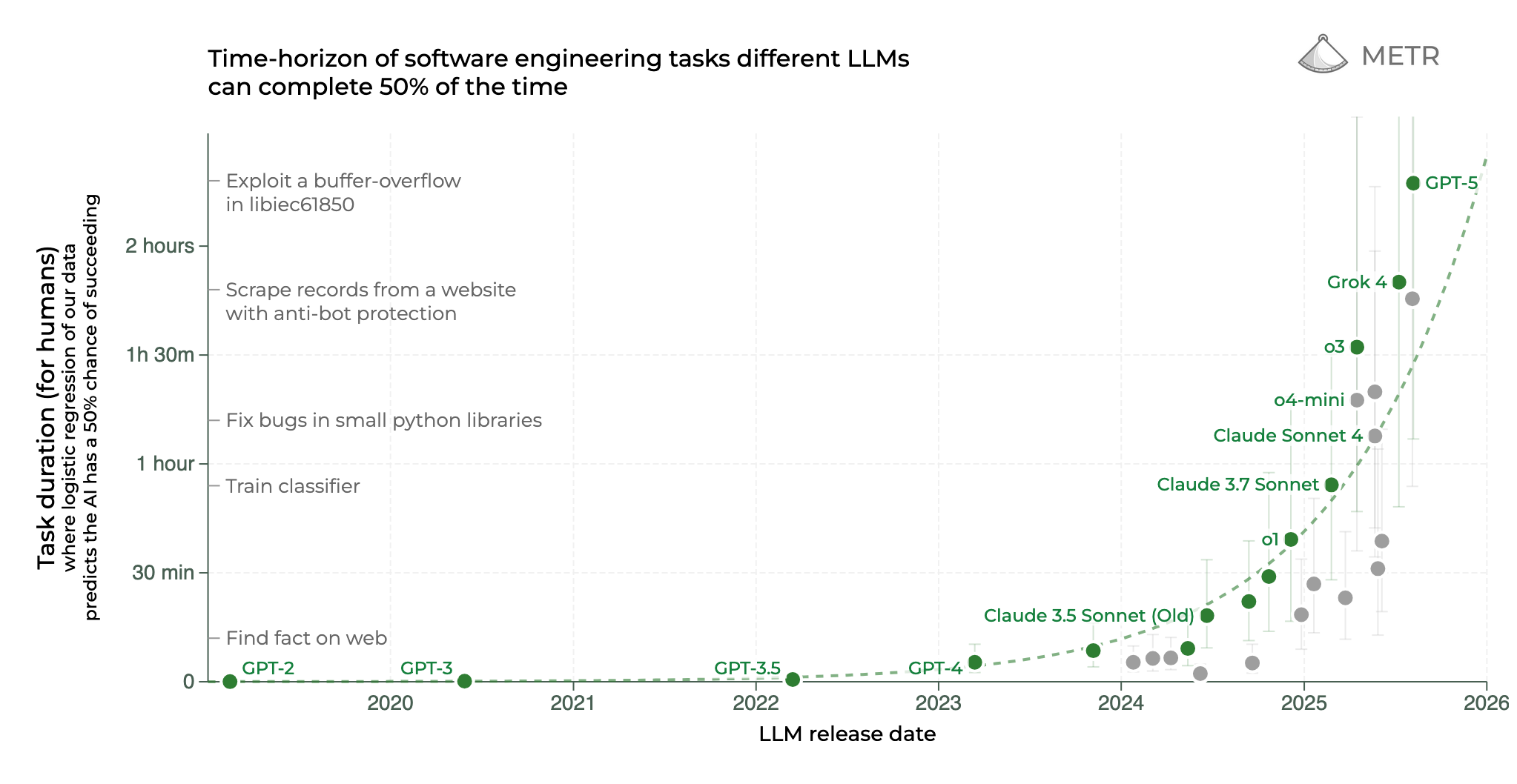
每一步的错误率低于 1%,你不觉得这可疑吗?作为一名智能体编程工具(我现在用的是 Codex CLI)的日常用户,要是 GPT-5 真能 99.9% 的时间都完美搞定我的任务,我敢把鞋吃了。
我的经验直觉告诉我,即便是现在最强的 AI,正确的可能性也到不了 95%。那么,差距从何而来?我们需要仔细看看那篇论文的原文:
我们的任务通常使用的环境,除非被智能体直接操作,否则不会发生显著变化。相比之下,真实的任务常常发生在不断变化的环境中。 […] 同样,我们的任务中很少有那种一步错就满盘皆输的情况。这部分是为了降低收集人类基线数据的预期成本。
这和我平时干的活儿完全是两码事。
METR 也承认现实世界的混乱。他们为自己的任务设计了一个“混乱度评级”,而他们任务的“平均混乱度”只有 3.2/16。
根据 METR 的定义,我平时接触的大部分软件工程工作的混乱度至少在 7-8 分左右,我甚至处理过混乱度高达 13/16 的问题。
任务混乱度每增加 1 点,平均成功率大约下降 8.1%。
根据 METR 测得的混乱度影响进行推断,在处理时长 2 小时的任务时,GPT-5 的成功率将从 70% 骤降至 40% 左右。这就和我实际体验到的情况对上号了。
我不确定单靠智能本身就能解决混乱度的问题。对环境的混沌和现实的模糊性的鲁棒性,本质上是关于如何管理好上下文。在我们找到解决这个问题的灵丹妙药之前,很明显,我们需要一个能将问题分解成工作单元的工作流,并通过可验证的检查点来管理错误的累积。
这些可验证的检查点,必须是人类能够理解的。
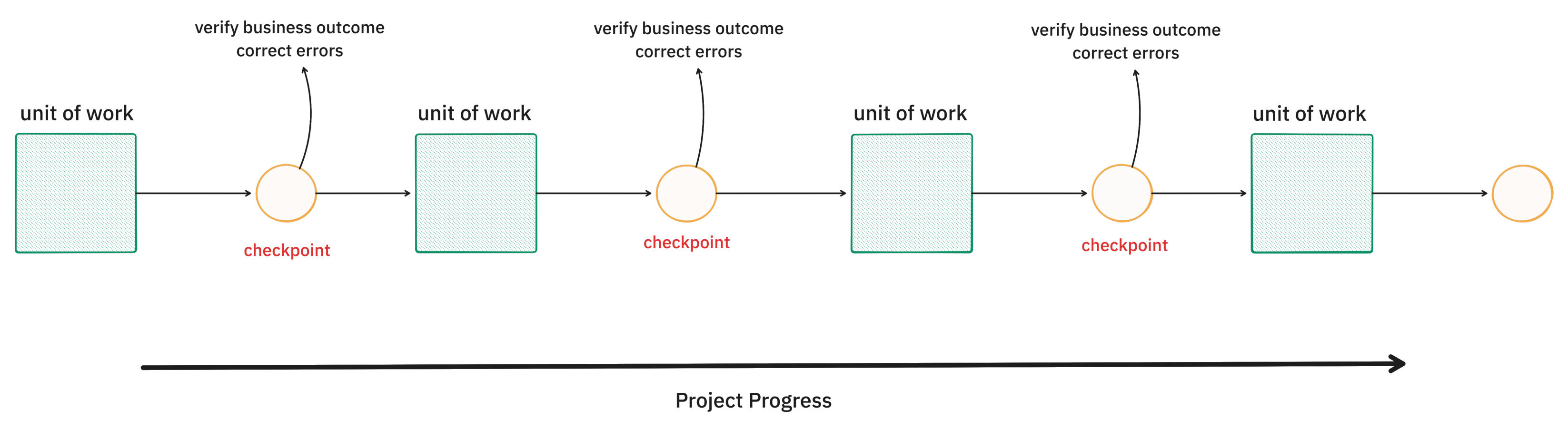
那么,到底什么才是“大小合适”的工作单元?
大小合适的工作单元需要足够小,并且能简明扼要地描述预期成果。
在完成一个工作单元后,其预期成果必须是人类能够理解的。我主张,它需要提供清晰可辨的商业价值。归根结底,软件的用户将是人类(或模拟人类构造的系统)。因此,一个优雅的项目分解方式,就是将其建模为一个个小的工作单元,并在每个检查点提供清晰的商业价值。这既能满足大语言模型上下文窗口的要求,也有助于管理错误的传播。
软件工程师其实早就定义了一种能提供商业价值、并能容纳所有上下文和范围协商的工作单元——那就是“用户故事”(User Stories)。我认为,它们是一个很好的起点,可以帮助我们将大问题分解成大语言模型能够一次性解决的小问题,同时提供具体的结果。它们以用户成果为中心,与“任务”不同,用户成果在软件开发的混乱动态环境中具有很强的鲁棒性。
可交付的商业价值也是所有利益相关者都能理解和协作的基础。软件不是由开发人员在真空中构建的——它需要团队、产品负责人、业务人员和用户的协调。AI 智能体在自己独立的上下文环境中工作,与其他利益相关者脱节,这会损害其效率和价值的传递。我认为这是一个需要弥合的重要鸿沟。
| 单元大小 | 完成后的产出 |
待办事项 | 小 | 渐进的技术价值 |
“计划模式” | 大 | 技术价值 |
亚马逊 Kiro 规范 | 小 | 技术价值 |
用户故事 | 小 | 商业价值 |
如今大多数 AI 智能体都有运行良好的“计划”模式。这些模式能让智能体不偏离轨道,但它们提供的主要是技术价值,而不一定是清晰的商业成果。我相信,规划我提议的这种工作单元是与现有规划工具互补的。而且,由于前面提到的上下文退化问题,我认为这种方式要优于对一个庞大的工作单元进行规划。
当然,敏捷开发 (Agile) 圣经里描述的传统用户故事本身还不够。它需要配上一些“额外的东西”,来引导智能体收集正确的上下文,从而服务于故事所描述的商业价值成果。至于这个“额外的东西”具体是什么样,我们希望在未来几个月里找到答案。
StoryMachine 实验
为了测试“用户故事 + 额外的东西”是否真能成为我上面描述的那种最优工作单元,我们正在进行一个名为 StoryMachine 的实验。目前 StoryMachine 的功能还很简单——它会读取你的产品需求文档 (PRD) 和技术规格 (Tech Specs),然后生成故事卡片。这还只是个开始。但我们将建立一个评估系统,帮助我们迭代出一种能让我们毫不费力地构建有用软件的工作单元描述方式。我希望在未来几个月里,能和大家分享我们的发现。
我希望 AI 辅助开发这门手艺能变得更轻松,别再像玩老虎机一样全凭运气。而要实现这一点,我们最好的杠杆就是管理好工作单元。
原文链接:https://blog.nilenso.com/blog/2025/09/15/ai-unit-of-work/